前言
JavaScript源码经过了词法分析和语法分析的处理就产生了语法分析树,接下来的工作就是将语法分析树转换为字节码,也就是本文将要讲述的内容。上述的整个过程实际上就是任何一门程序语言必经的步骤——编译。但是不同于许多语言(C/C++/Objective-C),JavaScript编译结束之后,并不会生成存放在硬盘之中的目标代码或可执行文件,生成的指令字节码,可能会立即被虚拟机进行逐行解释执行,也有可能被缓存下来通过JIT技术转换为本地代码。
CodeCache
在开篇中,我们提到如下的图: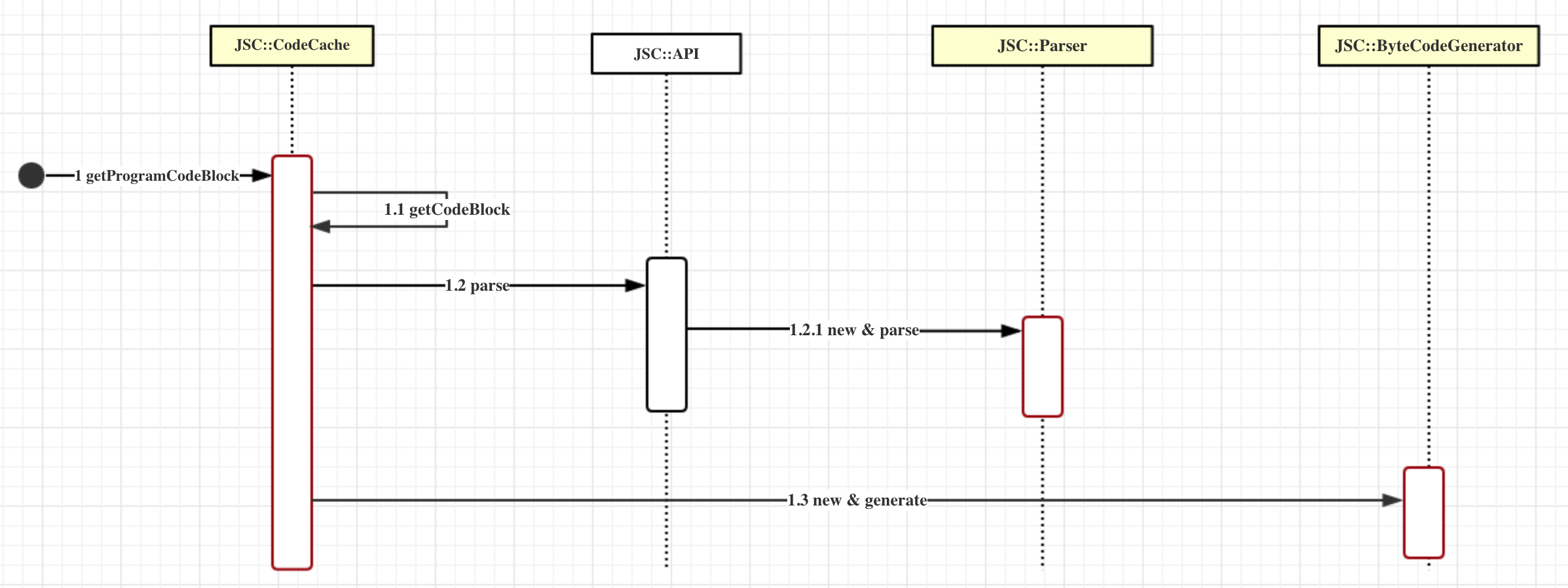
当语法分析结束后,就该CodeCache大显身手了,从名字就可以推断出,它负责CodeBlock的缓存处理1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16class CodeCache {
public:
CodeCache();
~CodeCache();
UnlinkedProgramCodeBlock* getProgramCodeBlock(VM&, ProgramExecutable*, const SourceCode&, JSParserBuiltinMode, JSParserStrictMode, DebuggerMode, ParserError&);
UnlinkedEvalCodeBlock* getEvalCodeBlock(VM&, EvalExecutable*, const SourceCode&, JSParserBuiltinMode, JSParserStrictMode, DebuggerMode, ParserError&, EvalContextType, const VariableEnvironment*);
UnlinkedModuleProgramCodeBlock* getModuleProgramCodeBlock(VM&, ModuleProgramExecutable*, const SourceCode&, JSParserBuiltinMode, DebuggerMode, ParserError&);
UnlinkedFunctionExecutable* getFunctionExecutableFromGlobalCode(VM&, const Identifier&, const SourceCode&, ParserError&);
private:
template <class UnlinkedCodeBlockType, class ExecutableType>
UnlinkedCodeBlockType* getGlobalCodeBlock(VM&, ExecutableType*, const SourceCode&, JSParserBuiltinMode, JSParserStrictMode, DebuggerMode, ParserError&, EvalContextType, const VariableEnvironment*);
CodeCacheMap m_sourceCode;
};
m_sourceCode是容器,用来存储CodeBlock
CodeCache有4个getXXXCodeBlock,用来获取各种CodeBlock,其中前3个都会调到getGlobalCodeBlock方法:
1 | template <class UnlinkedCodeBlockType, class ExecutableType> |
getFunctionExecutableFromGlobalCode比较特殊:
1 | UnlinkedFunctionExecutable* CodeCache::getFunctionExecutableFromGlobalCode(VM& vm, const Identifier& name, const SourceCode& source, ParserError& error) |
它并没有返回CodeBlock,而是返回一个UnlinkedFunctionExecutable,然而在UnlinkedFunctionExecutable内部的方法generateUnlinkedFunctionCodeBlock实际上也调用了BytecodeGenerator::generate:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29static UnlinkedFunctionCodeBlock* generateUnlinkedFunctionCodeBlock(
VM& vm, UnlinkedFunctionExecutable* executable, const SourceCode& source,
CodeSpecializationKind kind, DebuggerMode debuggerMode,
UnlinkedFunctionKind functionKind, ParserError& error, SourceParseMode parseMode)
{
JSParserBuiltinMode builtinMode = executable->isBuiltinFunction() ? JSParserBuiltinMode::Builtin : JSParserBuiltinMode::NotBuiltin;
JSParserStrictMode strictMode = executable->isInStrictContext() ? JSParserStrictMode::Strict : JSParserStrictMode::NotStrict;
std::unique_ptr<FunctionNode> function = parse<FunctionNode>(
&vm, source, executable->name(), builtinMode, strictMode, executable->parseMode(), executable->superBinding(), error, nullptr);
if (!function) {
return nullptr;
}
function->finishParsing(executable->name(), executable->functionMode());
executable->recordParse(function->features(), function->hasCapturedVariables());
bool isClassContext = executable->superBinding() == SuperBinding::Needed;
// 生成一个UnlinkedFunctionCodeBlock
UnlinkedFunctionCodeBlock* result = UnlinkedFunctionCodeBlock::create(&vm, FunctionCode, ExecutableInfo(function->usesEval(), function->isStrictMode(), kind == CodeForConstruct, functionKind == UnlinkedBuiltinFunction, executable->constructorKind(), executable->superBinding(), parseMode, executable->derivedContextType(), false, isClassContext, EvalContextType::FunctionEvalContext), debuggerMode);
// 调用`BytecodeGenerator`生成字节码
error = BytecodeGenerator::generate(vm, function.get(), result, debuggerMode, executable->parentScopeTDZVariables());
if (error.isValid()) return nullptr;
return result;
}
最终下来,BytecodeGenerator的探索显得格外重要了
BytecodeGenerator
BytecodeGenerator名如其意:字节码生成器。它对外有一个类方法generate,里面调用了它的构造函数生成一个临时的BytecodeGenerator变量,并调用其不带参数的generate方法返回是否是解析错误,而真正的字节码结果存放在第3个参数CodeBlock中1
2
3
4
5
6template<typename... Args>
static ParserError generate(VM& vm, Args&& ...args)
{
auto bytecodeGenerator = std::make_unique<BytecodeGenerator>(vm, std::forward<Args>(args)...);
return bytecodeGenerator->generate();
}
接下来看下它的几个私有构造函数:1
2
3
4
5
6
7
8
9
10
11
12
13class BytecodeGenerator
{
BytecodeGenerator(VM&, ProgramNode*, UnlinkedProgramCodeBlock*, DebuggerMode, const VariableEnvironment*);
BytecodeGenerator(VM&, FunctionNode*, UnlinkedFunctionCodeBlock*, DebuggerMode, const VariableEnvironment*);
BytecodeGenerator(VM&, EvalNode*, UnlinkedEvalCodeBlock*, DebuggerMode, const VariableEnvironment*);
BytecodeGenerator(VM&, ModuleProgramNode*, UnlinkedModuleProgramCodeBlock*, DebuggerMode, const VariableEnvironment*);
~BytecodeGenerator();
...
private:
Strong<UnlinkedCodeBlock> m_codeBlock;
}
可以看到,BytecodeGenerator需要注入以下几个参数,其中除了DebuggerMode外,任何一个参数,都可能是一个篇幅讲述不完的,所以尽量讲的简要一点。
- VM 虚拟机
- Node,有
ProgramNode、FunctionNode、EvalNode和ModuleProgramNode4种UnlinkedCodeBlock,和Node相对应,有UnlinkedProgramCodeBlock、UnlinkedFunctionCodeBlock、UnlinkedEvalCodeBlock和UnlinkedModuleProgramCodeBlock4种- DebuggerMode 是否是调试模式
- VariableEnvironment 变量环境
参数分析
VM
如枚举VMType所示,VM有3种类型:1
enum VMType { Default, APIContextGroup, APIShared }`
1 | // WebCore has a one-to-one mapping of threads to VMs; |
VM的定义如下:
其中构造函数是私有的,外部不可访问,另外还罗列了一些我认为重要的成员变量1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55class VM : public ThreadSafeRefCounted<VM> {
public:
// VM的APIShared创建方式:单例
bool isSharedInstance() { return vmType == APIShared; }
bool usingAPI() { return vmType != Default; }
JS_EXPORT_PRIVATE static bool sharedInstanceExists();
JS_EXPORT_PRIVATE static VM& sharedInstance();
// VM的Default创建方式
JS_EXPORT_PRIVATE static Ref<VM> create(HeapType = SmallHeap);
JS_EXPORT_PRIVATE static Ref<VM> createLeaked(HeapType = SmallHeap);
// VM的APIContextGroup创建方式
static Ref<VM> createContextGroup(HeapType = SmallHeap);
...
private:
// 锁
RefPtr<JSLock> m_apiLock;
public:
ExecutableAllocator executableAllocator;
Heap heap;
VMType vmType;
VMEntryFrame* topVMEntryFrame;
ExecState* topCallFrame;
// a large numer of Structure
Strong<Structure> structureStructure;
Strong<Structure> structureRareDataStructure;
Strong<Structure> terminatedExecutionErrorStructure;
Strong<Structure> stringStructure;
Strong<Structure> propertyNameIteratorStructure;
Strong<Structure> propertyNameEnumeratorStructure;
Strong<Structure> customGetterSetterStructure;
Strong<Structure> scopedArgumentsTableStructure;
Strong<Structure> apiWrapperStructure;
Strong<Structure> JSScopeStructure;
Strong<Structure> executableStructure;
Strong<Structure> nativeExecutableStructure;
Strong<Structure> evalExecutableStructure;
Strong<Structure> programExecutableStructure;
Strong<Structure> functionExecutableStructure;
...
PrototypeMap prototypeMap;
SourceProviderCacheMap sourceProviderCacheMap;
Interpreter* interpreter;
...
ExecState* newCallFrameReturnValue;
ExecState* callFrameForCatch;
...
ExecState是执行脚本的对象,由GlobalObject管理的,负责记录脚本执行上下文
Node
在语法分析篇中,我们提到了Node的继承图,其中本文提到的4中Node均继承自ScopeNode,而ScopeNode继承自StatementNode,显然这4种Node属于基本语句,并且和区域范围有关。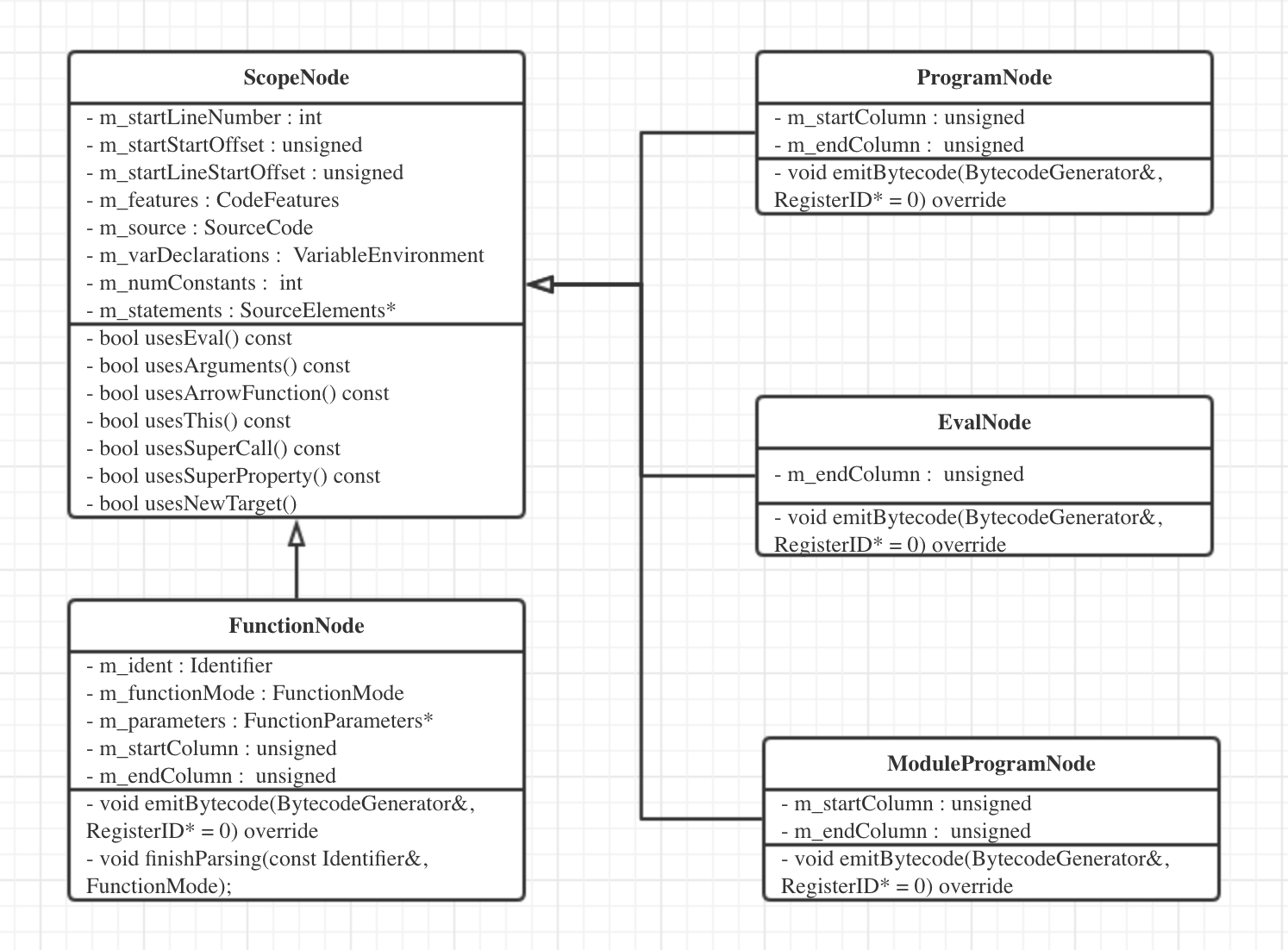
UnlinkedCodeBlock
UnlinkedCodeBlock是代码管理类,主要有UnlinkedProgramCodeBlock、UnlinkedFunctionCodeBlock、UnlinkedEvalCodeBlock和UnlinkedModuleProgramCodeBlock4种。它存储的是 编译后的ByteCode ,它的继承层级如下图所示: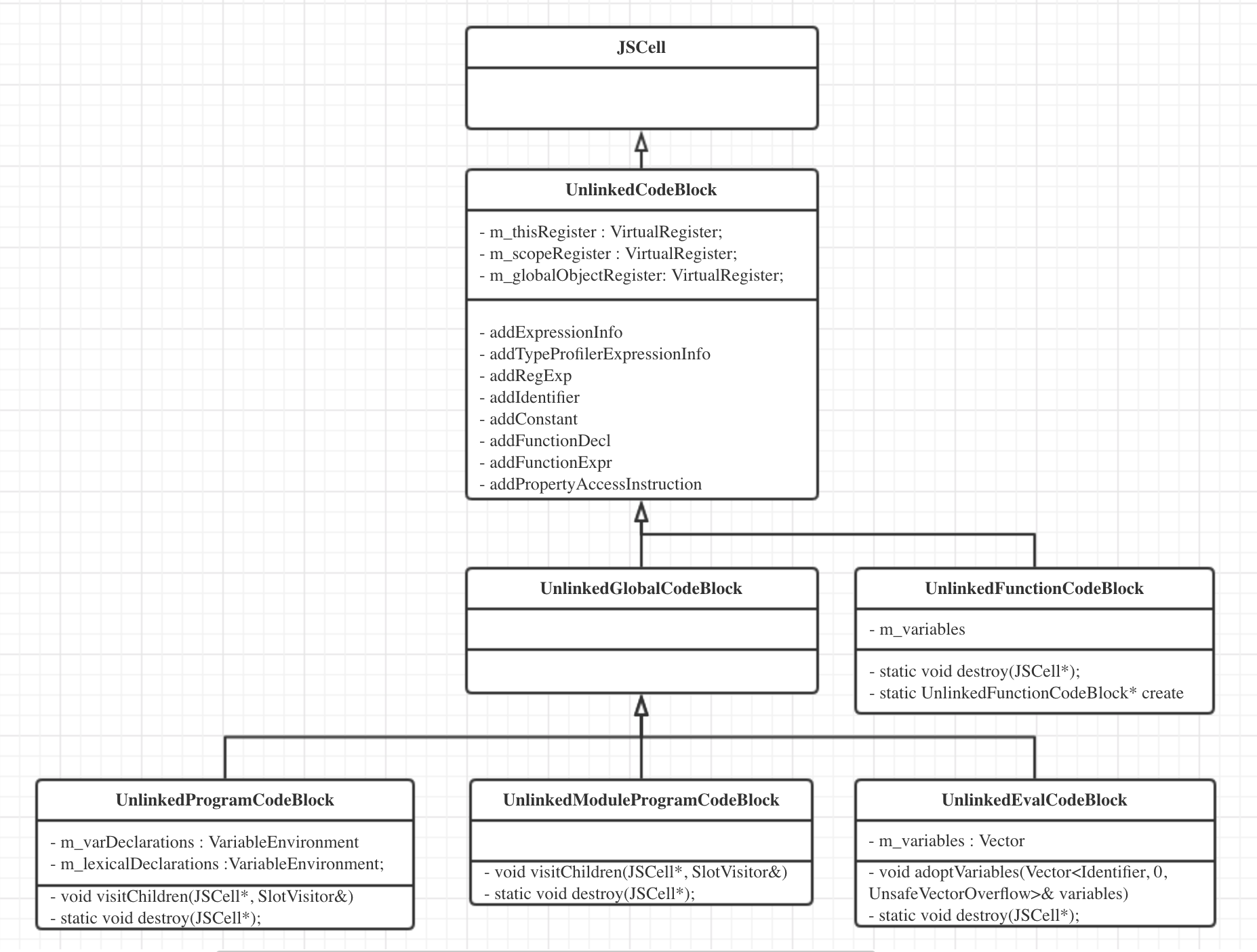
与之对应的还有一个CodeBlock,主要用于LLint和JIT,它的继承层级和UnlinkedCodeBlock极其类似,我们后续的系列篇章中会提到。
VariableEnvironment
VariableEnvironment有一个非常重要的成员变量m_map,它用来存放各种被标记的变量:1
Map m_map;
它的key为UniquedStringImpl*类型,value为枚举类型Traits1
2
3
4
5
6
7
8
9
10
11
12
13enum Traits : uint16_t
{
IsCaptured = 1 << 0,
IsConst = 1 << 1,
IsVar = 1 << 2,
IsLet = 1 << 3,
IsExported = 1 << 4,
IsImported = 1 << 5,
IsImportedNamespace = 1 << 6,
IsFunction = 1 << 7,
IsParameter = 1 << 8,
IsSloppyModeHoistingCandidate = 1 << 9
};
同时,它还有若干重要的方法,用来捕获和标记变量1
2
3
4
5
6
7
8bool hasCapturedVariables() const;
bool captures(UniquedStringImpl* identifier) const;
void markVariableAsCapturedIfDefined(const RefPtr<UniquedStringImpl>& identifier);
void markVariableAsCaptured(const RefPtr<UniquedStringImpl>& identifier);
void markAllVariablesAsCaptured();
void markVariableAsImported(const RefPtr<UniquedStringImpl>& identifier);
void markVariableAsExported(const RefPtr<UniquedStringImpl>& identifier);
从这些方法名和枚举值可以简单地推测出:它主要用来标识变量的上下文,例如是否是闭包中捕获的变量,是否是导入的变量等
generate
接下来就该分析核心函数generate了:
1 | ParserError BytecodeGenerator::generate() |
emitBytecode
前文提到的4种Node均继承自ScopeNode,所以这里展开多态性分析:
ProgramNode
1 | void ProgramNode::emitBytecode(BytecodeGenerator& generator, RegisterID*) |
1 | static void emitProgramNodeBytecode(BytecodeGenerator& generator, ScopeNode& scopeNode) |
调用堆栈如下:1
2
3ProgramNode::emitBytecode
└──emitProgramNodeBytecode
└──emitStatementsBytecode
ModuleProgramNode
1 | void ModuleProgramNode::emitBytecode(BytecodeGenerator& generator, RegisterID*) |
可以看到ModuleProgramNode和ProgramNode两者的emitBytecode调用堆栈是一致的,这里不再重复分析。
调用堆栈如下:1
2
3ModuleProgramNode::emitBytecode
└──emitProgramNodeBytecode
└──emitStatementsBytecode
EvalNode
1 | void EvalNode::emitBytecode(BytecodeGenerator& generator, RegisterID*) |
调用堆栈如下:1
2EvalNode::emitBytecode
└──emitStatementsBytecode
FunctionNode
FunctionNode的字节码生成比较麻烦,它区分了几种解析模式:1
2
3
4
5
6
7
8
9
10
11
12enum class SourceParseMode : uint8_t {
NormalFunctionMode,
GeneratorBodyMode,
GeneratorWrapperFunctionMode,
GetterMode,
SetterMode,
MethodMode,
ArrowFunctionMode,
ProgramMode,
ModuleAnalyzeMode,
ModuleEvaluateMode
};
其中前7种都算是Funtion的范畴,这里针对GeneratorWrapperFunctionMode和GeneratorBodyMode做了单独解析处理,其它的走默认解析方式
1 | void FunctionNode::emitBytecode(BytecodeGenerator& generator, RegisterID*) |
GeneratorWrapperFunctionMode和GeneratorBodyMode都包含了Generator,推测应该和ES6推出的Genetator 函数有关,这里简单提一下:
形式上,Generator 函数是一个普通函数,但是有两个特征。一是,function关键字与函数名之间有一个星号;二是,函数体内部使用yield表达式,定义不同的内部状态.
GeneratorBodyMode样式如下:1
2
3
4
5
6
7function* helloWorldGenerator() {
yield 'hello';
yield 'world';
return 'ending';
}
var hw = helloWorldGenerator();
GeneratorWrapperFunctionMode的样式如下:
1 | function *gen(a, b = hello()) |
简单认识一下,这里不会深究,因为最终关心的是字节码的生成。可以看到,不管是以上哪种Node的emitBytecode,最后都不可避免地走到了emitStatementsBytecode。毕竟不管是ProgramNode、EvalNode,还是FunctionNode,都是由一些基本的语句组成的,因此Bytecode的生成最终会和语法分析篇中提到的各种Node扯上关系。同时也可以合理推测到:emitStatementsBytecode只是一个起点,绝对不是终点,在里面可能会有各种递归循环调用在等待着我们。。。

