前言
在JavaScriptCore引擎深度解析3—词法分析篇一文中,我们提到:Lexer是作为Parser的一个成员而存在的,主要目的就是为Parser提供一个个的JSToken,依赖图如下: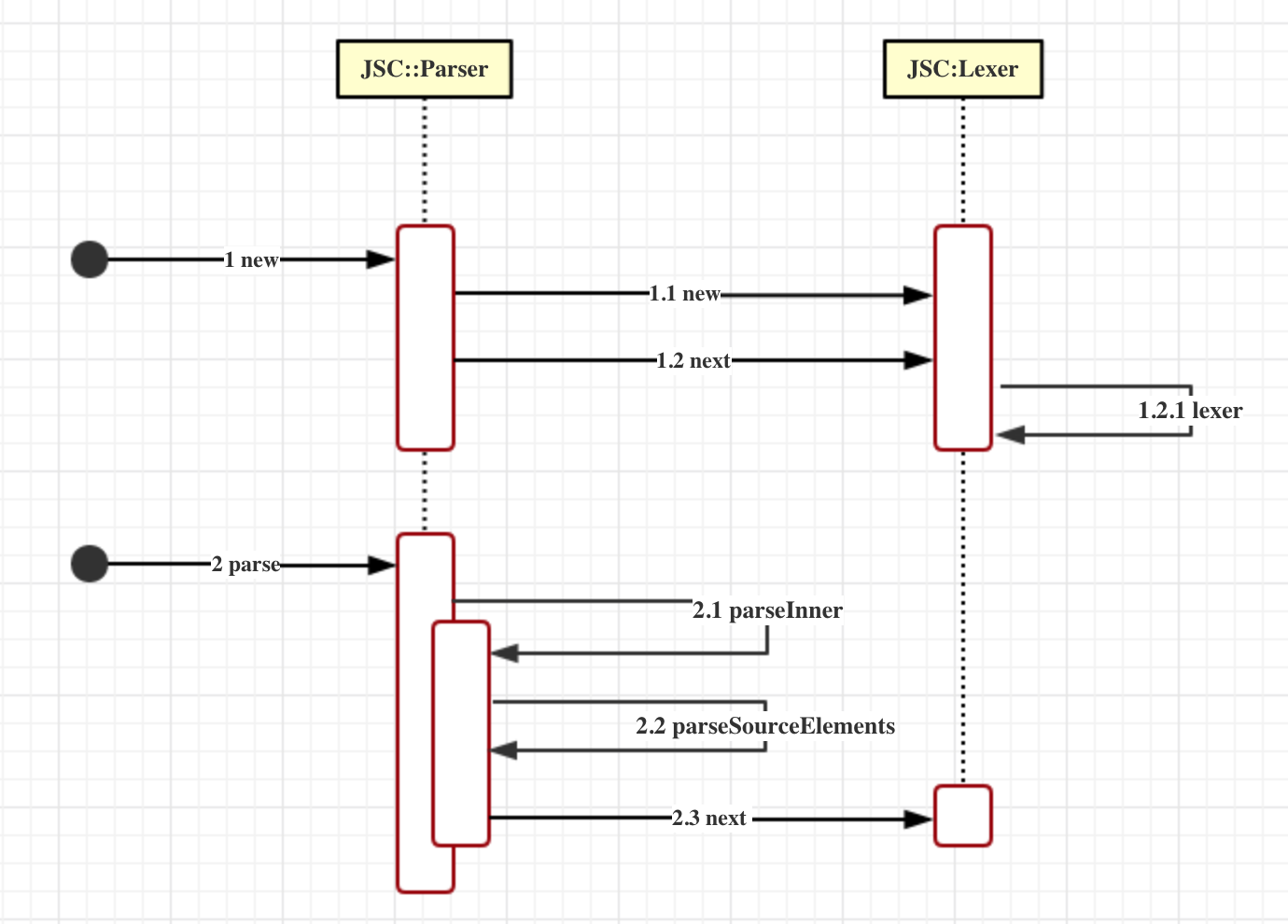
可以看到,词法分析篇花费了大量篇幅,也仅仅是讲了讲图的上半部分,即使如此,有些东西都是浅尝辄止,还有很多东西都未能讲到,因为源码实在是过于庞大,我的能力又实在过于有限…
路漫漫其修远兮……
不管怎样,词法分析篇也算是为我们的继续分析打了一些基础,我们继续来分析,尽可能在本篇把上图的下半部分分析完成。
注:有些源码过长,为了代码清晰便于分析,会删除一些逻辑,这并不意味这删除的代码逻辑不重要,如果想看全部源码,建议去看下源码工程对应的文件
语法分析概述
我们知道编译原理的语法分析有自顶向下和自底向上两种:
自顶向下分析法:从分析树的顶部(根节点)向底部(叶节点)方向构造分析树,而递归下降分析是自顶向下语法分析的通用形式,它可能需要回溯,导致效率较低,所以会引入预测分析,通过在输入中向前看固定个数(k)符号来选择正确的产生式,其中最典型的就是LL(1)文法(消除二义性、消除左递归、消除回溯)。在LL(1)文法的基础上,甚至会继续计算文法的FIRST集、FOLLOW集和SELECT集,进一步引入预测分析表,根据预测分析表进行产生式的选择。
自底向上分析法:从分析树的底部(叶节点)向顶部(根节点)方向构造分析树,而自底向上语法分析的通用框架是”移入-归约分析”,而LR文法是最大的、可以构造出相应
移入-归约语法分析器的文法类,最具代表性的有LR(0)、SLR、LR(1)、LASR几类。
而我们本文要讨论的JavaScript的语法分析采用的递归下降法,这是一种适合手写语法编译器的方法,且非常简单。递归下降法对语言所用的文法有一些限制,但递归下降是现阶段主流的语法分析方法,因为它可以由开发人员高度控制,在提供错误信息方面也很有优势。
语法树
我们知道,JavaScriptCore词法分析的输入是一个个的JSToken,而输出是一棵语法分析树。
例如,我们有如下的JavaScript代码:1
2
3
4
5
6
7
8
9
10function foo(x) {
var sum = 0;
if (x > 10) {
while(x > 0){
sum += x;
x--;
}
}
return sum;
}
通过语法分析将得到如下的简化版本语法树: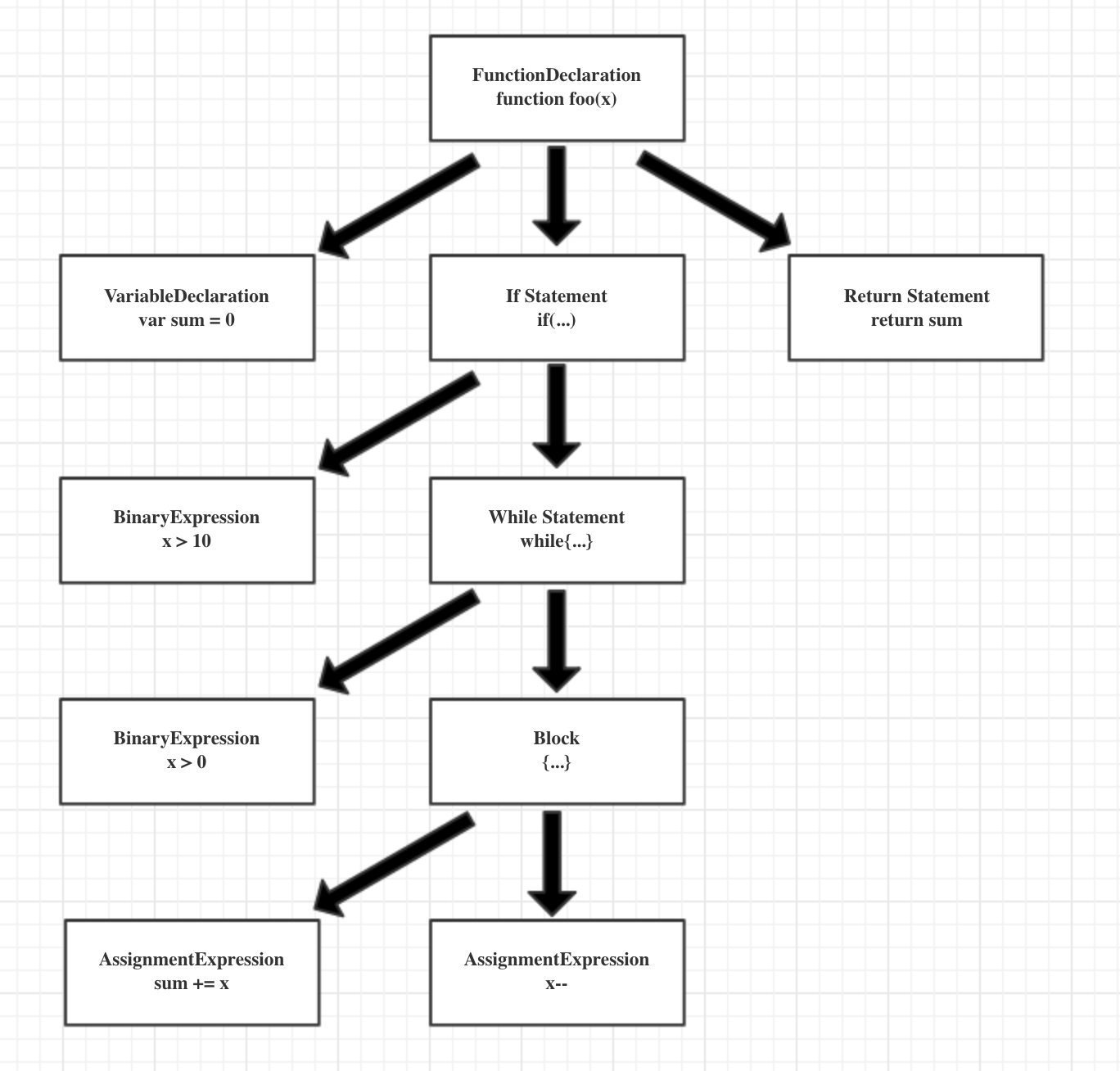
语法树节点
在了解语法树细节之前,我们先来看下语法树的节点,如下图所示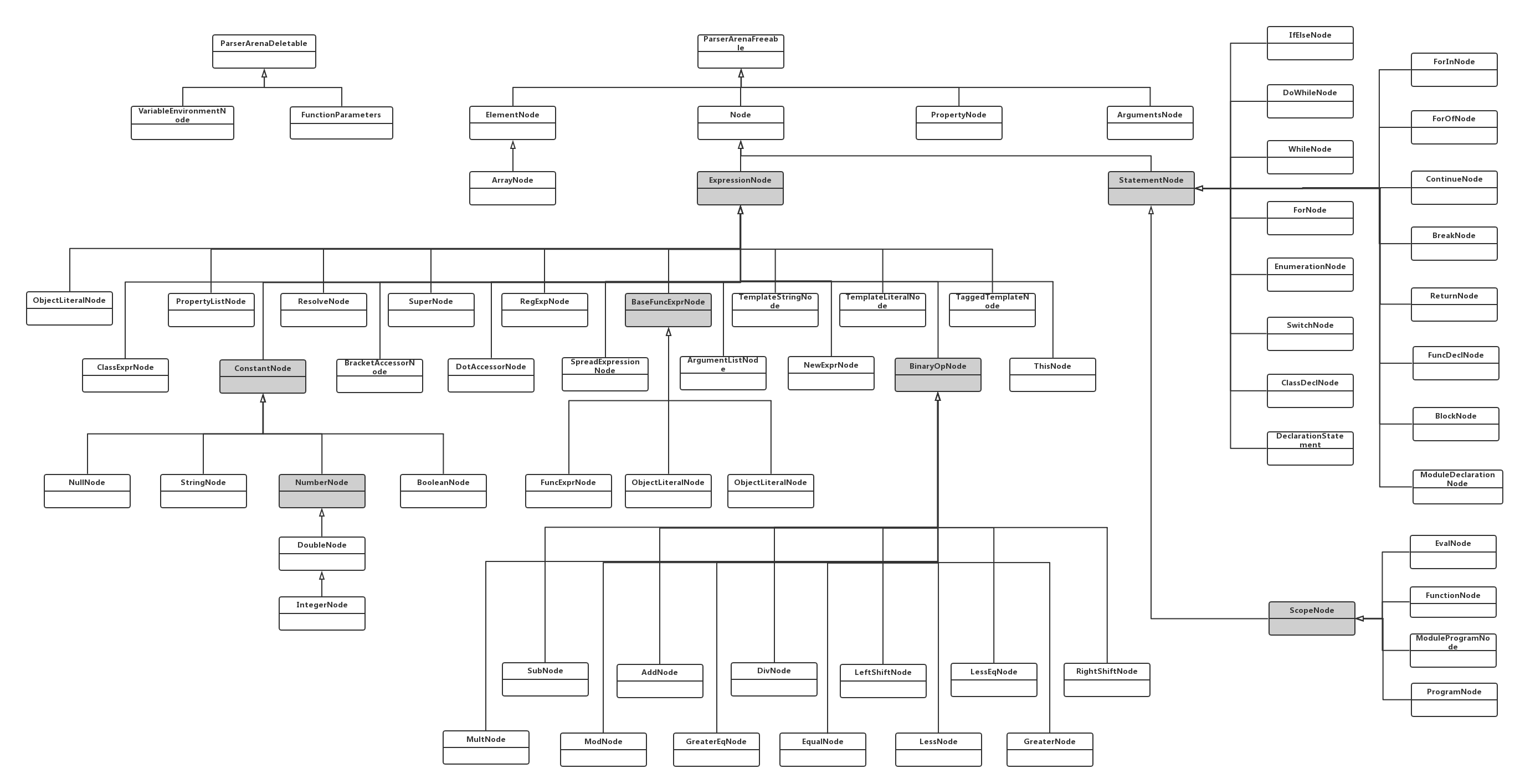
高清版本传送门
上图容纳了语法分析树中的绝大部分节点,可以看出,最重要的节点当属ExpressionNode和StatementNode节点,图中的大部分节点都继承自这两个节点。
StatementNode,基本语句节点,它的子节点主要是用来描述语言结构,例如
(1)顺序结构:ClassDeclNode、DeclarationStateMentNode
(2)条件结构:IFElseNode、SwitchNode
(3)循环结构:WhileNode、ForNode、DoWhileNode
(4)还有一个主要的节点是ScopeNode,用来描述区域ExpressionNode,表达式节点,它的子节点主要用来描述各种表达式
(1)ConstantNode,常量节点,它又衍生出字符串节点、Bool节点、整形、浮点型节点
(2)BinaryOpNode,两目运算符,衍生出加、减、乘、除、模、左移、右移等运算符节点
(3)此外,还有正则表达式节点、this节点、super节点等
节点内存管理
ParserArenaFreeable & ParserArenaDeletable
从图中可以看出,大部分Node节点追溯到根节点,都会到ParserArenaFreeable类,它重写了C++的new操作符,主要是实现自己的内存管理方式,不再是默认的的new、delete对象机制。如果熟悉C++,就会发现这和C++的placement new/delete的机制如出一辙:它主要是反复使用一块较大的动态分配成功的内存来构造不同类型的对象或者它们的数组。例如可以先申请一个足够大的字符数组,然后当需要时在它上面构造不同类型的对象或数组。它不用担心内存分配失败,因为它根本不分配内存,它只是调用对象的构造函数。
1 | class ParserArenaFreeable { |
- ParserArenaFreeable objects are freed when the arena is deleted.
Destructors are not called. Clients must not call delete on such objects
注意:ParserArenaFreeable的析构函数是不会被调用的,所以Node节点如果继承自ParserArenaFreeable,就不要去实现析构函数了,即使写了,也不会被调用!
例如,用如下方式创建一个字符串节点StringNode,其中ParserArena& m_parserArena1
2
3
4ExpressionNode* createString(const JSTokenLocation& location, const Identifier* string)
{
return new (m_parserArena) StringNode(location, *string);
}
实际上还有一个ParserArenaDeletable,它和ParserArenaFreeable很类似,除了 可以调用析构函数,所以要想节点被调用析构函数,做一些释放逻辑的话,可以选择继承ParserArenaDeletable。1
2
3
4
5 class ParserArenaDeletable {
public:
virtual ~ParserArenaDeletable() { }
void* operator new(size_t, ParserArena&);
};
- ParserArenaDeletable objects are deleted when the arena is deleted.
Destructors can be called. Clients must not call delete directly on such objects.
如果想进一步探索内存分配机制,可以看下类ParserArena的实现:
1、两个比较重要的alloc方法1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29void* allocateFreeable(size_t size)
{
// 字节对齐
size_t alignedSize = alignSize(size);
// 如果当前的内存块不够,进行扩容,并将扩容地址记录到m_freeablePools中
if ((m_freeablePoolEnd - m_freeableMemory) < alignedSize))
allocateFreeablePool();
// 分配地址
void* block = m_freeableMemory;
// 修改可用地址数值
m_freeableMemory += alignedSize;
return block;
}
void* allocateDeletable(size_t size)
{
// 首先调用allocateFreeable进行内存分配
ParserArenaDeletable* deletable = static_cast<ParserArenaDeletable*>(allocateFreeable(size));
// 将分配的地址添加到m_deletableObjects容器中,方便后续调用析构函数
m_deletableObjects.append(deletable);
// 返回地址
return deletable;
}
2、ParserArena的析构函数
首先对于m_deletableObjects的每个对象,要调用其析构函数,然后将之前记录到m_freeablePools中的每个地址都进行释放1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21ParserArena::~ParserArena()
{
deallocateObjects();
}
inline void ParserArena::deallocateObjects()
{
// 调用析构函数
size_t size = m_deletableObjects.size();
for (size_t i = 0; i < size; ++i)
m_deletableObjects[i]->~ParserArenaDeletable();
//
if (m_freeablePoolEnd)
fastFree(freeablePool());
// 释放所有申请的地址块
size = m_freeablePools.size();
for (size_t i = 0; i < size; ++i)
fastFree(m_freeablePools[i]);
}
ASTBuilder
ASTBuilder用来构建语法树AST,它主要包含以下成员:
- 一个虚拟机m_vm;
- 内存管理类
ParserArena;- 源代码类
SourceCode;- Scope;
- 4个栈容器;
1 | class ASTBuilder |
Vector
Vector不同于STL的vector,它是Webkit基础类库里面的一个工具类,位于:webkit-master/Source/WTF/wtf/Vector.h,这里的模板参数声明如下:1
template<typename T, size_t inlineCapacity = 0, typename OverflowHandler = CrashOnOverflow, size_t minCapacity = 16>
- 第1个参数代表存放的数据类型;
- 第2个参数代表容量;
- 第3个参数代表溢出异常处理,默认处理方案
CrashOnOverflow,这里给的是UnsafeVectorOverflow,这两种异常处理方案最后都会走向CRASH();- 第4个参数代表最小的容量,这里我们没有传,将使用默认值16;
操作数 BinaryOperand
1 | typedef int BinaryOperand; |
二元操作结构体
1 | struct BinaryOpInfo |
赋值操作结构体
1 | struct AssignmentInfo |
其中Operator是一个枚举:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17enum Operator
{
OpEqual,
OpPlusEq,
OpMinusEq,
OpMultEq,
OpDivEq,
OpPlusPlus,
OpMinusMinus,
OpAndEq,
OpXOrEq,
OpOrEq,
OpModEq,
OpLShift,
OpRShift,
OpURShift
};
parse堆栈
JavsScriptCore的语法分析起始于parse方法,parse的核心在parseInner方法,parseInner方法的两个参数类型分别是Identifier和SourceParseMode。Identifier前文提到过,代表标识符,而SourceParseMode是一个枚举:1
2
3
4
5
6
7
8
9
10
11
12
13enum class SourceParseMode : uint8_t
{
NormalFunctionMode,
GeneratorBodyMode,
GeneratorWrapperFunctionMode,
GetterMode,
SetterMode,
MethodMode,
ArrowFunctionMode,
ProgramMode,
ModuleAnalyzeMode,
ModuleEvaluateMode
};
parse方法的内部调用流程大概如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29parse
└──parseInner
└──parseArrowFunctionSingleExpressionBodySourceElements(箭头函数)
└──parseModuleSourceElements(模块导入导出)
└──parseGeneratorFunctionSourceElements
└──parseSourceElements
└──parseStatementListItem(语句列表)
└──parseVariableDeclaration(变量声明var、let)
└──parseClassDeclaration(类声明)
└──parseFunctionDeclaration(方法声明)
└──parseExpressionOrLabelStatement(表达式或者标签)
└──parseStatement(基本语句)
└──parseBlockStatement
└──parseVariableDeclaration
└──parseFunctionDeclaration
└──parseIfStatement
└──parseDoWhileStatement
└──parseWhileStatement
└──parseForStatement
└──parseContinueStatement
└──parseBreakStatement
└──parseReturnStatement
└──parseWithStatement
└──parseSwitchStatement
└──parseThrowStatement
└──parseTryStatement
└──parseExpressionOrLabelStatement
└──parseExpressionStatement
└──parseExpression
其中有些语句是相互嵌套的,例如,parseIfStatement里面可以继续调用parseStatement。由于这些代码规模较为庞大,不可能逐个分析到,本文将挑选下面的路径做一个大致的分析:1
2
3
4
5
6
7
8
9parse
└──parseInner
└──parseSourceElements
└──parseStatementListItem(语句列表)
└──parseStatement(基本语句)
└──parseVariableDeclaration
└──parseWhileStatement
└──parseExpressionStatement
└──parseExpression
parseInner
1 | // 进行语法分析,生成抽象语法树(为了代码清晰,省略了部分代码) |
parseSourceElements
1 | template <typename LexerType> |
parseStatementListItem
1 | template <typename LexerType> |
parseStatement
可以看到基本语句的解析都是通过switch分支来进行的1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100template <typename LexerType>
template <class TreeBuilder> TreeStatement Parser<LexerType>::parseStatement(TreeBuilder& context, const Identifier*& directive, unsigned* directiveLiteralLength)
{
DepthManager statementDepth(&m_statementDepth);
m_statementDepth++;
directive = 0;
int nonTrivialExpressionCount = 0;
failIfStackOverflow();
TreeStatement result = 0;
bool shouldSetEndOffset = true;
bool parentAllowsFunctionDeclarationAsStatement = m_immediateParentAllowsFunctionDeclarationInStatement;
m_immediateParentAllowsFunctionDeclarationInStatement = false;
switch (m_token.m_type)
{
case OPENBRACE:
result = parseBlockStatement(context);
shouldSetEndOffset = false;
break;
case VAR:
result = parseVariableDeclaration(context, DeclarationType::VarDeclaration);
break;
case FUNCTION: {
DepthManager statementDepth(&m_statementDepth);
m_statementDepth = 1;
result = parseFunctionDeclaration(context);
break;
}
case SEMICOLON: {
JSTokenLocation location(tokenLocation());
next();
result = context.createEmptyStatement(location);
break;
}
case IF:
result = parseIfStatement(context);
break;
case DO:
result = parseDoWhileStatement(context);
break;
case WHILE:
result = parseWhileStatement(context);
break;
case FOR:
result = parseForStatement(context);
break;
case CONTINUE:
result = parseContinueStatement(context);
break;
case BREAK:
result = parseBreakStatement(context);
break;
case RETURN:
result = parseReturnStatement(context);
break;
case WITH:
result = parseWithStatement(context);
break;
case SWITCH:
result = parseSwitchStatement(context);
break;
case THROW:
result = parseThrowStatement(context);
break;
case TRY:
result = parseTryStatement(context);
break;
case DEBUGGER:
result = parseDebuggerStatement(context);
break;
case EOFTOK:
case CASE:
case CLOSEBRACE:
case DEFAULT:
// These tokens imply the end of a set of source elements
return 0;
case IDENT:
case YIELD: {
bool allowFunctionDeclarationAsStatement = false;
result = parseExpressionOrLabelStatement(context, allowFunctionDeclarationAsStatement);
break;
}
case STRING:
directive = m_token.m_data.ident;
if (directiveLiteralLength)
*directiveLiteralLength = m_token.m_location.endOffset - m_token.m_location.startOffset;
nonTrivialExpressionCount = m_parserState.nonTrivialExpressionCount;
FALLTHROUGH;
default:
TreeStatement exprStatement = parseExpressionStatement(context);
if (directive && nonTrivialExpressionCount != m_parserState.nonTrivialExpressionCount)
directive = 0;
result = exprStatement;
break;
}
if (result && shouldSetEndOffset)
context.setEndOffset(result, m_lastTokenEndPosition.offset);
return result;
}
parseExpression
1 | template <typename LexerType> |
parseAssignmentExpression
接下来重点分析下赋值表达式的解析:parseAssignmentExpression1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100template <typename LexerType>
template <typename TreeBuilder> TreeExpression Parser<LexerType>::parseAssignmentExpression(TreeBuilder& context, ExpressionErrorClassifier& classifier)
{
failIfStackOverflow();
JSTextPosition start = tokenStartPosition();
JSTokenLocation location(tokenLocation());
int initialAssignmentCount = m_parserState.assignmentCount;
int initialNonLHSCount = m_parserState.nonLHSCount;
bool maybeAssignmentPattern = match(OPENBRACE) || match(OPENBRACKET);
bool wasOpenParen = match(OPENPAREN);
bool isValidArrowFunctionStart = match(OPENPAREN) || match(IDENT);
SavePoint savePoint = createSavePoint();
size_t usedVariablesSize = 0;
if (wasOpenParen) {
usedVariablesSize = currentScope()->currentUsedVariablesSize();
currentScope()->pushUsedVariableSet();
}
if (match(YIELD) && !isYIELDMaskedAsIDENT(currentScope()->isGenerator()))
return parseYieldExpression(context);
// 解析左值
TreeExpression lhs = parseConditionalExpression(context);
// 箭头函数的分析,有的情况下会把一个箭头函数赋值给一个变量:var a = (a)=>a+2;
if (isValidArrowFunctionStart && !match(EOFTOK))
{
bool isArrowFunctionToken = match(ARROWFUNCTION);
if (!lhs || isArrowFunctionToken) {
SavePointWithError errorRestorationSavePoint = createSavePointForError();
restoreSavePoint(savePoint);
if (isArrowFunctionParameters()) {
if (wasOpenParen)
currentScope()->revertToPreviousUsedVariables(usedVariablesSize);
return parseArrowFunctionExpression(context);
}
restoreSavePointWithError(errorRestorationSavePoint);
if (isArrowFunctionToken)
failDueToUnexpectedToken();
}
}
...
if (initialNonLHSCount != m_parserState.nonLHSCount) {
return lhs;
}
int assignmentStack = 0;
Operator op;
bool hadAssignment = false;
while (true)
{
// 解析操作符
switch (m_token.m_type)
{
case EQUAL: op = OpEqual; break;
case PLUSEQUAL: op = OpPlusEq; break;
case MINUSEQUAL: op = OpMinusEq; break;
case MULTEQUAL: op = OpMultEq; break;
case DIVEQUAL: op = OpDivEq; break;
case LSHIFTEQUAL: op = OpLShift; break;
case RSHIFTEQUAL: op = OpRShift; break;
case URSHIFTEQUAL: op = OpURShift; break;
case ANDEQUAL: op = OpAndEq; break;
case XOREQUAL: op = OpXOrEq; break;
case OREQUAL: op = OpOrEq; break;
case MODEQUAL: op = OpModEq; break;
default:
goto end;
}
m_parserState.nonTrivialExpressionCount++;
hadAssignment = true;
context.assignmentStackAppend(assignmentStack, lhs, start, tokenStartPosition(), m_parserState.assignmentCount, op);
start = tokenStartPosition();
m_parserState.assignmentCount++;
next(TreeBuilder::DontBuildStrings);
// 解析
lhs = parseAssignmentExpression(context);
if (initialNonLHSCount != m_parserState.nonLHSCount) {
break;
}
}
end:
if (hadAssignment)
m_parserState.nonLHSCount++;
if (!TreeBuilder::CreatesAST)
return lhs;
while (assignmentStack)
lhs = context.createAssignment(location, assignmentStack, lhs, initialAssignmentCount, m_parserState.assignmentCount, lastTokenEndPosition());
return lhs;
}
StatementNode
接下来将挑选若干StatementNode的子类进行细节分析,这部分内容某种意义上也是为之后的字节码生成做一定的铺垫
DeclarationStatement
1 | class DeclarationStatement : public StatementNode { |
一个JavaScript变量的声明的代码篇幅,已经超出了我的想象:
parseVariableDeclaration
1 | template <typename LexerType> |
parseVariableDeclarationList
1 | template <typename LexerType> |
示例
一段js代码,一个变量的声明和赋值
1 | var age = 6 * 7; |
在经过Esprima语法分析后,会得到下面的结果:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34```json
{
"type": "Program",
"body": [
{
"type": "VariableDeclaration",
"declarations": [
{
"type": "VariableDeclarator",
"id": {
"type": "Identifier",
"name": "age"
},
"init": {
"type": "BinaryExpression",
"operator": "*",
"left": {
"type": "Literal",
"value": 6,
"raw": "6"
},
"right": {
"type": "Literal",
"value": 7,
"raw": "7"
}
}
}
],
"kind": "var"
}
],
"sourceType": "script"
}
WhileNode
1 | class WhileNode : public StatementNode { |
parseWhileStatement
1 | template <typename LexerType> |
示例
1 | while(a > 0){ |
在经过Esprima语法分析后,会得到下面的结果:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39{
"type": "Program",
"body": [
{
"type": "WhileStatement",
"test": {
"type": "BinaryExpression",
"operator": ">",
"left": {
"type": "Identifier",
"name": "a"
},
"right": {
"type": "Literal",
"value": 0,
"raw": "0"
}
},
"body": {
"type": "BlockStatement",
"body": [
{
"type": "ExpressionStatement",
"expression": {
"type": "UpdateExpression",
"operator": "--",
"argument": {
"type": "Identifier",
"name": "a"
},
"prefix": false
}
}
]
}
}
],
"sourceType": "script"
}
IfElseNode
1 | class IfElseNode : public StatementNode { |
一直觉得if语句的解析应该比较简单,但是看了parseIfStatement后,觉得并不是想象的那么容易:
如果是这样的if语句,相对来说比较容易理解,且语法树比较擅长这种形式;1
2if(con1){}
else{}
但是如果出现了下面的这种情况,就比较费劲了,因为语法树不太好表达这样的形式,所以需要将其转换成标准的“树形式”,转换的过程看下面的代码和图1
2
3
4
5if(con1) xxx;
else if(con2) xxx;
...
else if(conn) xxx;
else xxx;
parseIfStatement
1 | template <typename LexerType> |
上面讲了这么多,可能会感觉很迷糊,可能要问:为什么一个ifStatement要搞的这么复杂!里面为什么要用那么多栈?为什么还带着那么多循环?
先来解决第一个问题:
while (!exprStack.isEmpty())这个最后的while循环的目的是什么呢?
如图所示,它的目的就是将if ... else if ... else if... else的结构变成一个标准的if ... else结构,方便语法树的处理再来看第二个问题:
if (!trailingElse),如果没有最后的else,这里要单独处理的目的是什么
实际上有了第一个问题的铺垫,也不难理解了,它将不规范的if ... else if ... else if结构(不包含最后的else)变成标准的if ... else if ... else if... else结构了,方便第一个问题中while循环的处理。
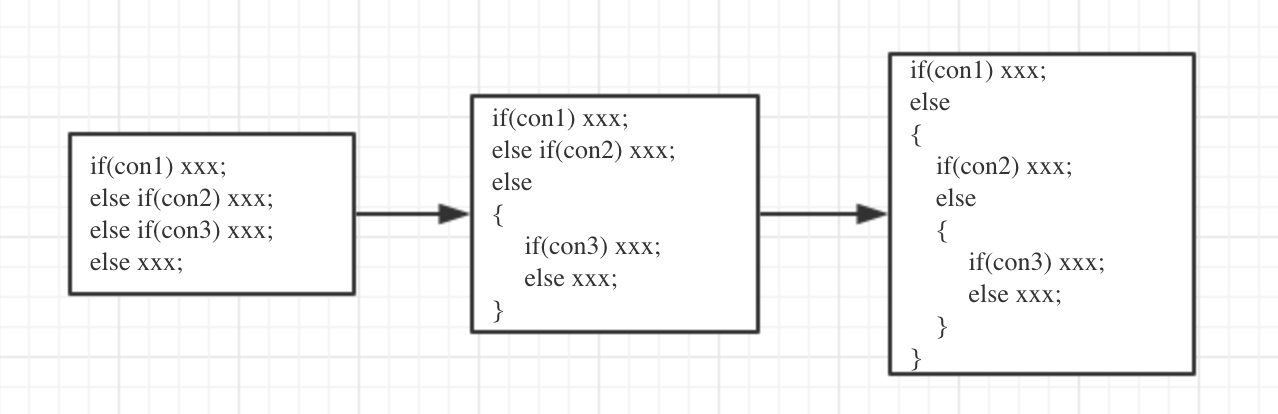
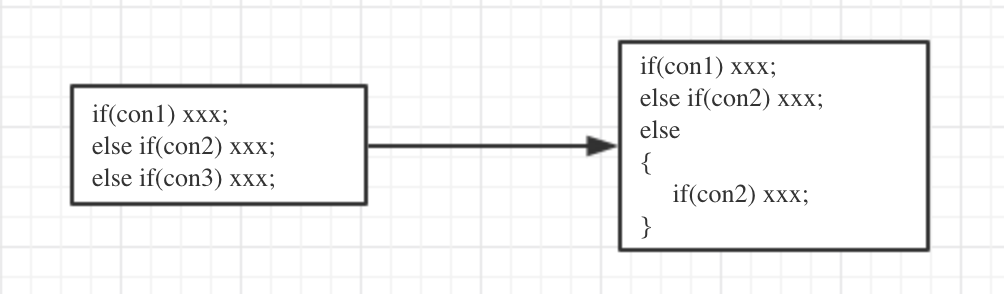
到了这里,不妨再回看下代码,应该会觉得比较清楚。
示例
来这里自己输入if语句看吧。
SwitchNode
1 | class SwitchNode : public StatementNode, public VariableEnvironmentNode |
parseSwitchStatement
1 | template <typename LexerType> |
1 | template <typename LexerType> |
大部分逻辑看代码中的注释应该就可以理解,这里比较费解的是:case语句解析了两次1
2TreeClauseList firstClauses = parseSwitchClauses(context);
TreeClauseList secondClauses = parseSwitchClauses(context);
原因是在switch语法中,defalut关键字的位置是不确定的,可能在开头,可能在结尾,也可能在中间,甚至还可能不存在。它相当于把switch所有的case劈成了两半,为了在遍历case的循环中不被defalut打断,所以这里采取了前后两次遍历,逻辑清晰,易于理解。
总结
语法分析涉及到的东西较大,篇幅有些多,后续可能会继续更新,添加一些细节分析。

