前言
词法分析是编译程序进行编译时第一个要进行的任务,主要是对源程序进行编译预处理(去除注释、无用的回车换行找到包含的文件等)之后,对整个源程序进行分解,分解成一个个单词,这些单词有且只有五类,分别是 标识符、关键字、常数、运算符、界符。以便为下面的语法分析和语义分析做准备。可以说词法分析面向的对象是单个的字符,目的是把它们组成有效的单词(字符串),那么该阶段的主要任务就是构造一个词法分析器。有以下两种方法:
- 手工写,就是对于一种特定的语言,例如
JavaScript,我们手工敲代码根据该语言规则来模拟出这个转化过程,这种方法虽然复杂,并且容易出错,但这样对词法分析各个部分都有比较精确的控制,并且效率可能会比较高。- 自动生成一个词法分析器,过程就是:声明式的规范–>自动生成–>词法分析器,这里自动生成是一个工具,那么它所接受的输入是声明式的规范,输出是一个词法分析,我们先来看下输入声明式规范,声明式规范的意思是我们只需写出识别字符流的规则是什么,不需要指出怎么识别,然后放进自动生成器就行了,那么这个声明式的规范是什么?它就是我们所学的正则表达式,我们所学的C语言的关键字,标识符,整数都是正则表达式,也就是说我们将这些正则表达式放进自动生成器,那么就会生成词法分析器,这个词法分析器就是DFA,确定状态有限自动机。那么很明显这个自动生成器整个过程实际上是正则表达式转化为非确定的有限状态自动机(NFA),最后非确定的有限状态自动机转化为确定状态有限自动机,然后通过DFA的最小化,就生成了最后的DFA,也就是我们的输出词法分析器。如果输入的代码可以被有限自动机所接受,那么将会进入语法分析的阶段
词法分析及语法分析,最著名的工具就是lex/yacc,以及后继者flex/bison(The LEX & YACC Page)。它们为很多软件提供了语言或文本解析的功能,相当强大,也很有趣。
虽然JavaScriptCore并没有使用它们,而是自行编写实现的,但基本思路是相似的。
数据类型
按照惯例,还是从一些用到的基本数据类型说起.
CharacterType类型
JavaScript语言中有如下的字符类型,是针对每一个字符而言的1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45// JavaScriptCore/parser/Lexer.cpp
enum CharacterType {
// Types for the main switch
// The first three types are fixed, and also used for identifying
// ASCII alpha and alphanumeric characters (see isIdentStart and isIdentPart).
CharacterIdentifierStart,
CharacterZero,
CharacterNumber,
CharacterInvalid,
CharacterLineTerminator,
CharacterExclamationMark,
CharacterOpenParen,
CharacterCloseParen,
CharacterOpenBracket,
CharacterCloseBracket,
CharacterComma,
CharacterColon,
CharacterQuestion,
CharacterTilde,
CharacterQuote,
CharacterBackQuote,
CharacterDot,
CharacterSlash,
CharacterBackSlash,
CharacterSemicolon,
CharacterOpenBrace,
CharacterCloseBrace,
CharacterAdd,
CharacterSub,
CharacterMultiply,
CharacterModulo,
CharacterAnd,
CharacterXor,
CharacterOr,
CharacterLess,
CharacterGreater,
CharacterEqual,
// Other types (only one so far)
CharacterWhiteSpace,
CharacterPrivateIdentifierStart
};
JSTokenType类型
JavaScript中的JSTokenType类型如下,可以看到JavaScript的每个关键字,算术运算符、逻辑运算符都被列为一种JSToken类型(由于JSTokenType较多,有一些尚未列出…)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46// JavaScriptCore/parser/ParseTokens.h
enum JSTokenType {
NULLTOKEN = KeywordTokenFlag,
TRUETOKEN,
FALSETOKEN,
BREAK,
CASE,
DEFAULT,
FOR,
NEW,
VAR,
LET,
CONSTTOKEN,
CONTINUE,
FUNCTION,
RETURN,
IF,
THISTOKEN,
DO,
WHILE,
SWITCH,
WITH,
RESERVED,
RESERVED_IF_STRICT,
THROW,
TRY,
CATCH,
FINALLY,
DEBUGGER,
ELSE,
IMPORT,
EXPORT,
YIELD,
CLASSTOKEN,
EXTENDS,
SUPER,
OPENBRACE = 0,
CLOSEBRACE,
OPENPAREN,
CLOSEPAREN,
OPENBRACKET,
CLOSEBRACKET,
COMMA,
QUESTION,
...
在如下文件中可以看到上述枚举和关键词的映射关系(同样,由于篇幅关系,有些尚未列出)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41// JavaScriptCore/parser/Keywords.table
# Types.
null NULLTOKEN
true TRUETOKEN
false FALSETOKEN
# Keywords.
break BREAK
case CASE
catch CATCH
class CLASSTOKEN
const CONSTTOKEN
default DEFAULT
extends EXTENDS
finally FINALLY
for FOR
instanceof INSTANCEOF
new NEW
var VAR
let LET
continue CONTINUE
function FUNCTION
return RETURN
void VOIDTOKEN
delete DELETETOKEN
if IF
this THISTOKEN
do DO
while WHILE
else ELSE
in INTOKEN
super SUPER
switch SWITCH
throw THROW
try TRY
typeof TYPEOF
with WITH
debugger DEBUGGER
yield YIELD
...
Token类型
同时在源码中还可以看到一个枚举TokenType类型,这个类型是专门针对json的解析定义的,不要和前面的JSTokenType混淆(本来不应该在这里讲的,但是为了避免看源码混淆,还是提一下)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22// JavaScriptCore/runtime/LiteralParser.h
enum TokenType {
TokLBracket, // [
TokRBracket, // ]
TokLBrace, // {
TokRBrace, // }
TokString, // string
TokIdentifier, // identifier
TokNumber, // number
TokColon, // :
TokLParen, // (
TokRParen, // )
TokComma, // ,
TokTrue, // true
TokFalse, // false
TokNull, // null
TokEnd, // end
TokDot, // .
TokAssign, // =
TokSemi, // ;
TokError // error
};
JSToken类型
这个类型就比较重要了,将JavaScript源码通过词法分析过程之后,我们得到的就是一个个的JSToken了。可以看到它是一个复合类型
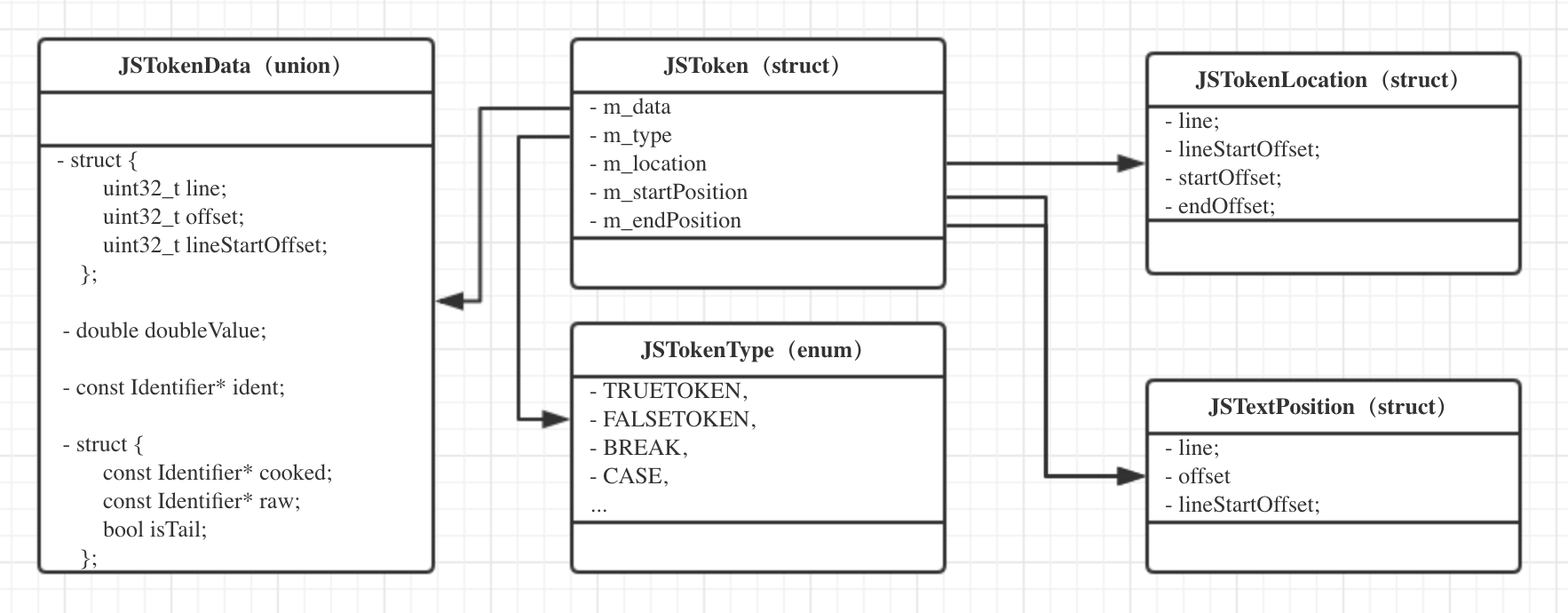
1 | struct JSToken { |
JSTokenData是一个联合体,可以存放以下4种成员,每个Token的数据的表示方式可能是不同的,例如
- 1、解析出来的数字字面值就可以用doubleValue来表示;
- 2、如果是字符串,可能就需要用第一个结构体来表示;
- 3、如果是方法名字或者变量名,需要Identifier来胜任;
1 | union JSTokenData { |
JSTokenLocation结构体包括行号、行起始位置、源文件起始位置、源文件结束位置1
2
3
4
5
6struct JSTokenLocation {
int line;
unsigned lineStartOffset;
unsigned startOffset;
unsigned endOffset;
};
JSTextPosition作为一个位置,有行号、源文件偏移、行偏移1
2
3
4
5struct JSTextPosition {
int line;
int offset;
int lineStartOffset;
};
词法分析过程
Lexer初始化
项目工程中,词法分析类Lexer类是辅助Parser类的,在Parser类中有一个成员变量m_lexer,在构造函数中对m_lexer进行了初始化:1
2
3
4
5
6
7
8
9
10// 定义
std::unique_ptr<LexerType> m_lexer;
// 构造函数中的初始化
m_lexer = std::make_unique<LexerType>(vm, builtinMode);
m_lexer->setCode(source, &m_parserArena);
m_token.m_location.line = source.firstLine();
m_token.m_location.startOffset = source.startOffset();
m_token.m_location.endOffset = source.startOffset();
m_token.m_location.lineStartOffset = source.startOffset();
标识符解析
然后在函数Parser类的方法nextExpectIdentifier中进行了调用,顾名思义,返回下一个期望的标识符1
2
3
4
5
6
7
8
9
10
11
12
13
14ALWAYS_INLINE void nextExpectIdentifier(unsigned lexerFlags = 0)
{
// 保存上一个Token的结束位置
int lastLine = m_token.m_location.line;
int lastTokenEnd = m_token.m_location.endOffset;
int lastTokenLineStart = m_token.m_location.lineStartOffset;
m_lastTokenEndPosition = JSTextPosition(lastLine, lastTokenEnd, lastTokenLineStart);
// 设置行号
m_lexer->setLastLineNumber(lastLine);
// 分析JSToken类型
m_token.m_type = m_lexer->lexExpectIdentifier(&m_token, lexerFlags, strictMode());
}
逻辑在lexExpectIdentifier方法中(删除了其中的一些Alert,便于代码清晰)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55template <typename T>
ALWAYS_INLINE JSTokenType Lexer<T>::lexExpectIdentifier(JSToken* tokenRecord, unsigned lexerFlags, bool strictMode)
{
JSTokenData* tokenData = &tokenRecord->m_data;
JSTokenLocation* tokenLocation = &tokenRecord->m_location;
const T* start = m_code;
const T* ptr = start;
const T* end = m_codeEnd;
JSTextPosition startPosition = currentPosition();
if (ptr >= end) {
goto slowCase;
}
// 必须是ASCII字符
if (!WTF::isASCIIAlpha(*ptr))
goto slowCase;
// 往后遍历,直到不是字母和数字,跳出循环
++ptr;
while (ptr < end) {
if (!WTF::isASCIIAlphanumeric(*ptr))
break;
++ptr;
}
// Here's the shift
if (ptr < end) {
if ((!WTF::isASCII(*ptr)) || (*ptr == '\\') || (*ptr == '_') || (*ptr == '$'))
goto slowCase;
m_current = *ptr;
} else
m_current = 0;
m_code = ptr;
// 创建一个标识符,JSTokenType = IDENT
if (lexerFlags & LexexFlagsDontBuildKeywords)
tokenData->ident = 0;
else
tokenData->ident = makeLCharIdentifier(start, ptr - start);
tokenLocation->line = m_lineNumber;
tokenLocation->lineStartOffset = currentLineStartOffset();
tokenLocation->startOffset = offsetFromSourcePtr(start);
tokenLocation->endOffset = currentOffset();
tokenRecord->m_startPosition = startPosition;
tokenRecord->m_endPosition = currentPosition();
m_lastToken = IDENT;
return IDENT;
slowCase:
// 核心逻辑
return lex(tokenRecord, lexerFlags, strictMode);
}
该方法存在的意义在于为标识符开了一条快速通道:因为源码中存在着大量的标识符,相对来说,关键字、常数、运算符、界符的数量就少一些,从概率角度来说,源码中每解析一个JSToken,结果是标识符的概率是比较大的,这样就可以节省时间,正如方法名所示,下一个期望的标识符。
核心逻辑
除了标识符的解析外,剩下的词法分析核心逻辑在lex方法中,具体逻辑请看代码以及注释(代码较长)1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
311
312
313
314
315
316
317
318
319
320
321
322
323
324
325
326
327
328
329
330
331
332
333
334
335
336
337
338
339
340
341
342
343
344
345
346
347
348
349
350
351
352
353
354
355
356
357
358
359
360
361
362
363
364
365
366
367
368
369
370
371
372
373
374
375
376
377
378
379
380
381
382
383
384
385
386
387
388
389
390
391
392
393
394
395
396
397
398
399
400
401
402
403
404
405
406
407
408
409
410
411
412
413
414
415
416
417
418
419
420
421
422
423
424
425
426
427
428
429
430
431
432
433
434
435
436
437
438
439
440
441
442
443
444
445
446
447
448
449
450
451
452
453
454
455
456
457
458
459
460
461
462
463
464
465
466
467
468
469
470
471
472
473
474
475
476
477
478
479
480
481
482
483
484
485
486
487
488
489
490
491
492
493
494
495
496
497
498
499
500
501
502
503
504
505
506
507
508
509
510
511
512
513
514
515
516
517
518
519
520
521
522
523
524
525
526
527
528
529
530
531
532
533
534
535
536
537
538
539
540
541
542
543
544
545
546
547
548
549
550
551
552
553
554
555
556
557
558
559
560
561
562
563
564
565
566
567
568
569
570
571
572
573
574
575
576
577
578
579
580
581
582
583
584
585
586
587
588
589
590
591
592
593
594
595template <typename T>
JSTokenType Lexer<T>::lex(JSToken* tokenRecord, unsigned lexerFlags, bool strictMode)
{
JSTokenData* tokenData = &tokenRecord->m_data;
JSTokenLocation* tokenLocation = &tokenRecord->m_location;
m_lastTokenLocation = JSTokenLocation(tokenRecord->m_location);
JSTokenType token = ERRORTOK;
m_terminator = false;
start:
// 跳过空格
skipWhitespace();
// 如果是结尾,返回EOFTOK类型
if (atEnd()) return EOFTOK;
tokenLocation->startOffset = currentOffset();
ASSERT(currentOffset() >= currentLineStartOffset());
tokenRecord->m_startPosition = currentPosition();
// 判断JSToken的首字符类型
CharacterType type;
if (LIKELY(isLatin1(m_current)))
// typesOfLatin1Characters是一个ASCII字符到CharacterType的映射表
type = static_cast<CharacterType>(typesOfLatin1Characters[m_current]);
else if (isNonLatin1IdentStart(m_current))
type = CharacterIdentifierStart;
else if (isLineTerminator(m_current))
type = CharacterLineTerminator;
else
type = CharacterInvalid;
switch (type) {
case CharacterGreater:
shift();
if (m_current == '>')
{
shift();
if (m_current == '>') {
shift();
if (m_current == '=') {
shift();
// >>>= 符号
token = URSHIFTEQUAL;
break;
}
// >>> 无符号逻辑右移
token = URSHIFT;
break;
}
if (m_current == '=') {
shift();
// >>= 符号
token = RSHIFTEQUAL;
break;
}
// >>逻辑右移
token = RSHIFT;
break;
}
// >= 大于等于符号
if (m_current == '=') {
shift();
token = GE;
break;
}
// > 大于符号
token = GT;
break;
case CharacterEqual:
{
if (peek(1) == '>') {
// Arrow Function(箭头函数): x => x * x
token = ARROWFUNCTION;
tokenData->line = lineNumber();
tokenData->offset = currentOffset();
tokenData->lineStartOffset = currentLineStartOffset();
ASSERT(tokenData->offset >= tokenData->lineStartOffset);
shift();
shift();
break;
}
shift();
if (m_current == '=') {
shift();
if (m_current == '=') {
shift();
// ===符号,全等(值和类型)
token = STREQ;
break;
}
// ==符号,判断是否相等
token = EQEQ;
break;
}
// 等于符号,赋值
token = EQUAL;
break;
}
case CharacterLess:
shift();
if (m_current == '!' && peek(1) == '-' && peek(2) == '-') {
// <!-- 单行注释
goto inSingleLineComment;
}
if (m_current == '<') {
shift();
if (m_current == '=') {
shift();
// <<=
token = LSHIFTEQUAL;
break;
}
// << 左移操作
token = LSHIFT;
break;
}
if (m_current == '=') {
shift();
// <= 小于等于
token = LE;
break;
}
// < 小于号
token = LT;
break;
case CharacterExclamationMark:
shift();
if (m_current == '=') {
shift();
if (m_current == '=') {
shift();
// !== 字符串不等于
token = STRNEQ;
break;
}
// != 不等于
token = NE;
break;
}
// ! 非操作
token = EXCLAMATION;
break;
case CharacterAdd:
shift();
if (m_current == '+') {
shift();
token = (!m_terminator) ? PLUSPLUS : AUTOPLUSPLUS;
break;
}
if (m_current == '=') {
shift();
// +=
token = PLUSEQUAL;
break;
}
// +操作
token = PLUS;
break;
case CharacterSub:
shift();
if (m_current == '-') {
shift();
if (m_atLineStart && m_current == '>') {
shift();
// 单行注释
goto inSingleLineComment;
}
token = (!m_terminator) ? MINUSMINUS : AUTOMINUSMINUS;
break;
}
if (m_current == '=') {
shift();
// -=操作
token = MINUSEQUAL;
break;
}
token = MINUS;
break;
case CharacterMultiply:
shift();
if (m_current == '=') {
shift();
// *=
token = MULTEQUAL;
break;
}
// *
token = TIMES;
break;
case CharacterSlash:
shift();
if (m_current == '/') {
shift();
// 单行注释
goto inSingleLineCommentCheckForDirectives;
}
if (m_current == '*') {
// 多行注释
shift();
if (parseMultilineComment())
goto start;
m_lexErrorMessage = ASCIILiteral("Multiline comment was not closed properly");
token = UNTERMINATED_MULTILINE_COMMENT_ERRORTOK;
goto returnError;
}
if (m_current == '=') {
shift();
// /=
token = DIVEQUAL;
break;
}
// / 除操作
token = DIVIDE;
break;
case CharacterAnd:
shift();
if (m_current == '&') {
shift();
// && 逻辑与
token = AND;
break;
}
if (m_current == '=') {
shift();
// &= 与等于
token = ANDEQUAL;
break;
}
// 与操作
token = BITAND;
break;
case CharacterXor:
shift();
if (m_current == '=') {
shift();
token = XOREQUAL;
break;
}
token = BITXOR;
break;
case CharacterModulo:
shift();
if (m_current == '=') {
shift();
token = MODEQUAL;
break;
}
token = MOD;
break;
case CharacterOr:
shift();
if (m_current == '=') {
shift();
// |= 操作
token = OREQUAL;
break;
}
if (m_current == '|') {
shift();
// || 逻辑或
token = OR;
break;
}
// 或操作
token = BITOR;
break;
case CharacterOpenParen:
// 左括号(
token = OPENPAREN;
tokenData->line = lineNumber();
tokenData->offset = currentOffset();
tokenData->lineStartOffset = currentLineStartOffset();
shift();
break;
case CharacterCloseParen:
// 右括号)
token = CLOSEPAREN;
shift();
break;
case CharacterOpenBracket:
// 左中括号[
token = OPENBRACKET;
shift();
break;
case CharacterCloseBracket:
// 右中括号]
token = CLOSEBRACKET;
shift();
break;
case CharacterComma:
// 逗号,
token = COMMA;
shift();
break;
case CharacterColon:
// 冒号:
token = COLON;
shift();
break;
case CharacterQuestion:
// 问号?
token = QUESTION;
shift();
break;
case CharacterTilde:
// ~符号
token = TILDE;
shift();
break;
case CharacterSemicolon:
// ;分号
shift();
token = SEMICOLON;
break;
case CharacterOpenBrace:
tokenData->line = lineNumber();
tokenData->offset = currentOffset();
tokenData->lineStartOffset = currentLineStartOffset();
shift();
// { 左大括号
token = OPENBRACE;
break;
case CharacterCloseBrace:
tokenData->line = lineNumber();
tokenData->offset = currentOffset();
tokenData->lineStartOffset = currentLineStartOffset();
shift();
// } 右大括号
token = CLOSEBRACE;
break;
case CharacterDot:
shift();
if (!isASCIIDigit(m_current)) {
if (UNLIKELY((m_current == '.') && (peek(1) == '.'))) {
shift();
shift();
/// ...符号
token = DOTDOTDOT;
break;
}
// .符号
token = DOT;
break;
}
goto inNumberAfterDecimalPoint;
case CharacterZero:
shift();
// 16进制的数字
if ((m_current | 0x20) == 'x') {
if (!isASCIIHexDigit(peek(1))) {
m_lexErrorMessage = ASCIILiteral("No hexadecimal digits after '0x'");
token = UNTERMINATED_HEX_NUMBER_ERRORTOK;
goto returnError;
}
// Shift out the 'x' prefix.
shift();
parseHex(tokenData->doubleValue);
if (isIdentStart(m_current)) {
m_lexErrorMessage = ASCIILiteral("No space between hexadecimal literal and identifier");
token = UNTERMINATED_HEX_NUMBER_ERRORTOK;
goto returnError;
}
token = tokenTypeForIntegerLikeToken(tokenData->doubleValue);
m_buffer8.shrink(0);
break;
}
// 2进制数字
if ((m_current | 0x20) == 'b') {
if (!isASCIIBinaryDigit(peek(1))) {
m_lexErrorMessage = ASCIILiteral("No binary digits after '0b'");
token = UNTERMINATED_BINARY_NUMBER_ERRORTOK;
goto returnError;
}
// Shift out the 'b' prefix.
shift();
parseBinary(tokenData->doubleValue);
if (isIdentStart(m_current)) {
m_lexErrorMessage = ASCIILiteral("No space between binary literal and identifier");
token = UNTERMINATED_BINARY_NUMBER_ERRORTOK;
goto returnError;
}
token = tokenTypeForIntegerLikeToken(tokenData->doubleValue);
m_buffer8.shrink(0);
break;
}
// 8进制数字
if ((m_current | 0x20) == 'o') {
if (!isASCIIOctalDigit(peek(1))) {
m_lexErrorMessage = ASCIILiteral("No octal digits after '0o'");
token = UNTERMINATED_OCTAL_NUMBER_ERRORTOK;
goto returnError;
}
// Shift out the 'o' prefix.
shift();
parseOctal(tokenData->doubleValue);
if (isIdentStart(m_current)) {
m_lexErrorMessage = ASCIILiteral("No space between octal literal and identifier");
token = UNTERMINATED_OCTAL_NUMBER_ERRORTOK;
goto returnError;
}
token = tokenTypeForIntegerLikeToken(tokenData->doubleValue);
m_buffer8.shrink(0);
break;
}
record8('0');
if (strictMode && isASCIIDigit(m_current)) {
m_lexErrorMessage = ASCIILiteral("Decimal integer literals with a leading zero are forbidden in strict mode");
token = UNTERMINATED_OCTAL_NUMBER_ERRORTOK;
goto returnError;
}
if (isASCIIOctalDigit(m_current)) {
if (parseOctal(tokenData->doubleValue)) {
token = tokenTypeForIntegerLikeToken(tokenData->doubleValue);
}
}
FALLTHROUGH;
case CharacterNumber:
if (LIKELY(token != INTEGER && token != DOUBLE))
{
if (!parseDecimal(tokenData->doubleValue)) {
token = INTEGER;
// 解析小数部分
if (m_current == '.') {
shift();
inNumberAfterDecimalPoint:
parseNumberAfterDecimalPoint();
// 可以肯定是一个小数,类型DOUBLE
token = DOUBLE;
}
// 解析指数部分
if ((m_current | 0x20) == 'e') {
if (!parseNumberAfterExponentIndicator()) {
m_lexErrorMessage = ASCIILiteral("Non-number found after exponent indicator");
token = atEnd() ? UNTERMINATED_NUMERIC_LITERAL_ERRORTOK : INVALID_NUMERIC_LITERAL_ERRORTOK;
goto returnError;
}
}
size_t parsedLength;
tokenData->doubleValue = parseDouble(m_buffer8.data(), m_buffer8.size(), parsedLength);
if (token == INTEGER)
token = tokenTypeForIntegerLikeToken(tokenData->doubleValue);
} else
token = tokenTypeForIntegerLikeToken(tokenData->doubleValue);
}
if (UNLIKELY(isIdentStart(m_current))) {
m_lexErrorMessage = ASCIILiteral("No identifiers allowed directly after numeric literal");
token = atEnd() ? UNTERMINATED_NUMERIC_LITERAL_ERRORTOK : INVALID_NUMERIC_LITERAL_ERRORTOK;
goto returnError;
}
m_buffer8.shrink(0);
break;
case CharacterQuote: {
// 引号",解析字符串
StringParseResult result = StringCannotBeParsed;
if (lexerFlags & LexerFlagsDontBuildStrings)
result = parseString<false>(tokenData, strictMode);
else
result = parseString<true>(tokenData, strictMode);
if (UNLIKELY(result != StringParsedSuccessfully)) {
token = result == StringUnterminated ? UNTERMINATED_STRING_LITERAL_ERRORTOK : INVALID_STRING_LITERAL_ERRORTOK;
goto returnError;
}
shift();
token = STRING;
break;
}
case CharacterBackQuote: {
// Skip backquote.
shift();
// 解析模板
StringParseResult result = StringCannotBeParsed;
if (lexerFlags & LexerFlagsDontBuildStrings)
result = parseTemplateLiteral<false>(tokenData, RawStringsBuildMode::BuildRawStrings);
else
result = parseTemplateLiteral<true>(tokenData, RawStringsBuildMode::BuildRawStrings);
if (UNLIKELY(result != StringParsedSuccessfully)) {
token = result == StringUnterminated ? UNTERMINATED_TEMPLATE_LITERAL_ERRORTOK : INVALID_TEMPLATE_LITERAL_ERRORTOK;
goto returnError;
}
token = TEMPLATE;
break;
}
case CharacterIdentifierStart:
ASSERT(isIdentStart(m_current));
FALLTHROUGH;
case CharacterBackSlash:
// 反斜杠 \
parseIdent:
if (lexerFlags & LexexFlagsDontBuildKeywords)
token = parseIdentifier<false>(tokenData, lexerFlags, strictMode);
else
token = parseIdentifier<true>(tokenData, lexerFlags, strictMode);
break;
case CharacterLineTerminator:
// ASCII 10和13
ASSERT(isLineTerminator(m_current));
shiftLineTerminator();
m_atLineStart = true;
m_terminator = true;
m_lineStart = m_code;
goto start;
case CharacterPrivateIdentifierStart:
if (m_parsingBuiltinFunction)
goto parseIdent;
FALLTHROUGH;
case CharacterInvalid:
m_lexErrorMessage = invalidCharacterMessage();
token = ERRORTOK;
goto returnError;
default:
RELEASE_ASSERT_NOT_REACHED();
m_lexErrorMessage = ASCIILiteral("Internal Error");
token = ERRORTOK;
goto returnError;
}
m_atLineStart = false;
goto returnToken;
inSingleLineCommentCheckForDirectives:
// Script comment directives like "//# sourceURL=test.js".
if (UNLIKELY((m_current == '#' || m_current == '@') && isWhiteSpace(peek(1)))) {
shift();
shift();
parseCommentDirective();
}
// Fall through to complete single line comment parsing.
inSingleLineComment:
while (!isLineTerminator(m_current)) {
if (atEnd())
return EOFTOK;
shift();
}
shiftLineTerminator();
m_atLineStart = true;
m_terminator = true;
m_lineStart = m_code;
if (!lastTokenWasRestrKeyword())
goto start;
token = SEMICOLON;
// Fall through into returnToken.
returnToken:
// 返回正常解析结果
tokenLocation->line = m_lineNumber;
tokenLocation->endOffset = currentOffset();
tokenLocation->lineStartOffset = currentLineStartOffset();
ASSERT(tokenLocation->endOffset >= tokenLocation->lineStartOffset);
tokenRecord->m_endPosition = currentPosition();
m_lastToken = token;
return token;
returnError:
// 异常结果
m_error = true;
tokenLocation->line = m_lineNumber;
tokenLocation->endOffset = currentOffset();
tokenLocation->lineStartOffset = currentLineStartOffset();
ASSERT(tokenLocation->endOffset >= tokenLocation->lineStartOffset);
tokenRecord->m_endPosition = currentPosition();
RELEASE_ASSERT(token & ErrorTokenFlag);
return token;
}
代码篇幅有些长,但是这是本篇最重要的一个函数,所以未作任何篇幅省略或缩减。
不过换一种方式看下,就会觉得比较清晰了,不妨结合来看。
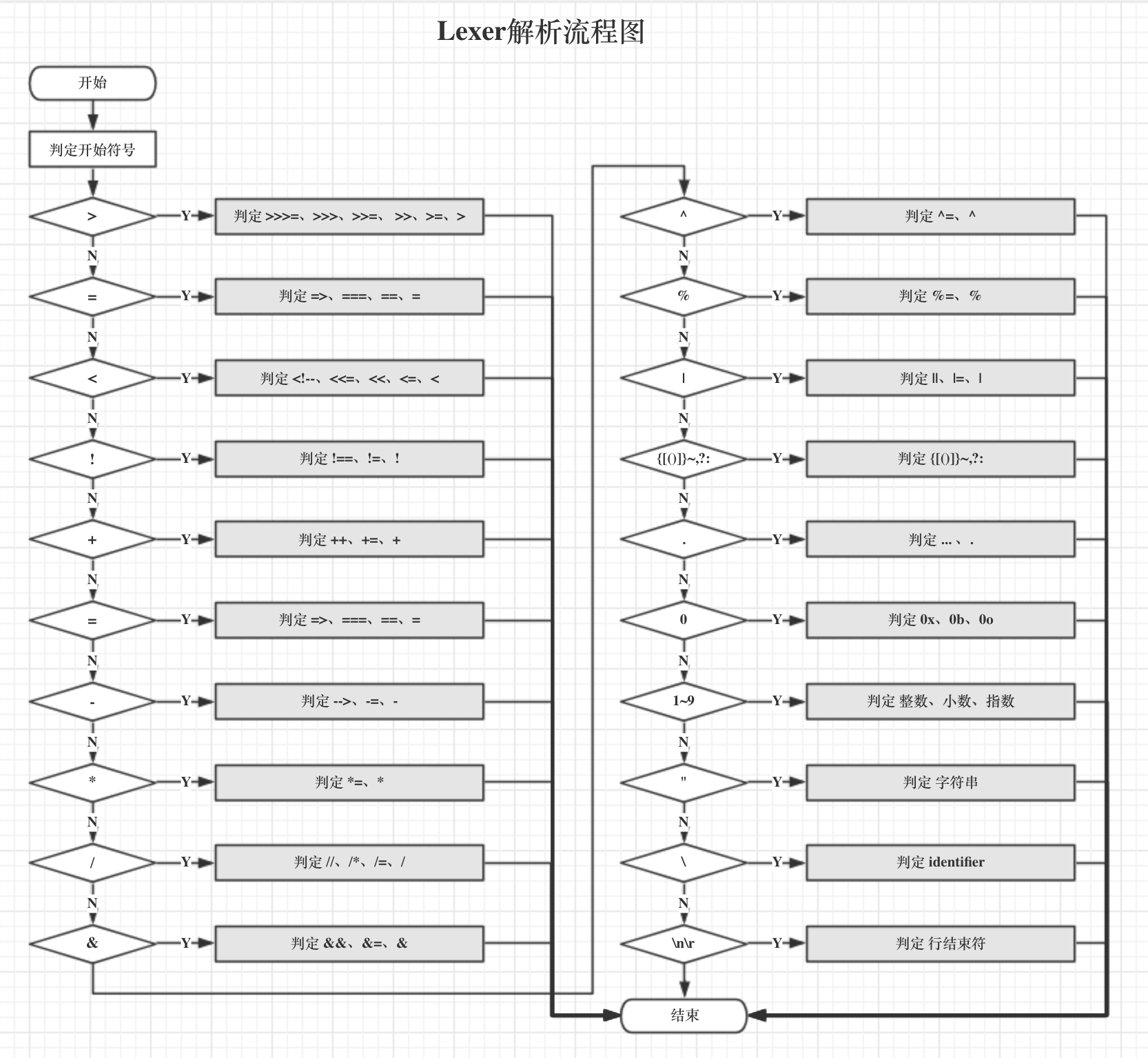
上述的switch语句过后,就产生了一个JSToken,其中大部分case都简单明了,易于理解,不过其中有几个重要的方法值得细看一下
字符串解析
1 | template <typename T> |
parseStringSlowCase的流程和和parseString的流程非常相似,都有转义字符、换行符的处理,以及最后的标识符的创建,不同的是parseStringSlowCase用的容器是m_buffer16,而parseString用的是m_buffer8
1 | typedef unsigned char LChar; |
1 | template <typename T> |
确定好了字符串的起始位置、长度和内容后,再来看下标识符的创建逻辑
1 | template <typename CharType> |
无论上述哪条路径,都离不开Identifier::fromString这个方法,这个方法已经涉及到了虚拟机,想一下:创建标识符肯定得经过虚拟机的记录,以便后续访问或者重复性的处理。这里不太适合分析下去,要不然泥潭就就出不去了,感兴趣的同学可以去看看。
10进制解析
先看下10进制数字的DFA图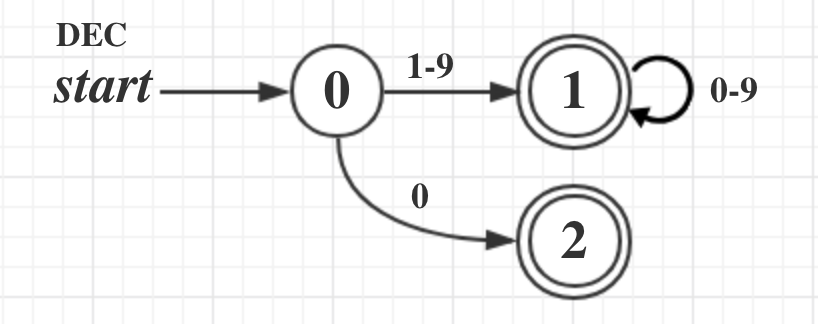
之后对解析到的10进制字符串进行求值,并将结果存放到returnValue中。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43template <typename T>
ALWAYS_INLINE bool Lexer<T>::parseDecimal(double& returnValue)
{
// Optimization: most decimal values fit into 4 bytes.
uint32_t decimalValue = 0;
// Since parseOctal may be executed before parseDecimal,
// the m_buffer8 may hold ascii digits.
if (!m_buffer8.size())
{
const unsigned maximumDigits = 10;
int digit = maximumDigits - 1;
// Temporary buffer for the digits. Makes easier
// to reconstruct the input characters when needed.
LChar digits[maximumDigits];
// 逐个遍历,每向右偏移一个字符,就将当前的decimalValue乘以10,
// 并加上(m_current - '0')
do {
decimalValue = decimalValue * 10 + (m_current - '0');
digits[digit] = m_current;
shift();
--digit;
} while (isASCIIDigit(m_current) && digit >= 0);
if (digit >= 0 && m_current != '.' && (m_current | 0x20) != 'e') {
// 如果没有小数点,也没有指数符号e,直接将decimalValue返回
returnValue = decimalValue;
return true;
}
for (int i = maximumDigits - 1; i > digit; --i)
record8(digits[i]);
}
// 出现了非数字字符,解析结果异常
while (isASCIIDigit(m_current)) {
record8(m_current);
shift();
}
return false;
}
16进制解析
首先看下如何去分析出一个16进制数字
然后计算该16进制的数字的值1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42template <typename T>
ALWAYS_INLINE void Lexer<T>::parseHex(double& returnValue)
{
// Optimization: 大部分的16进制数据,4个字节就可以存放下了
uint32_t hexValue = 0;
int maximumDigits = 7;
// toASCIIHexValue : character < 'A' ? character - '0' : (character - 'A' + 10) & 0xF
// 将结果hexValue左移4bit,计算当前的16进制字符对应的10进制值,加到hexValue中
do {
hexValue = (hexValue << 4) + toASCIIHexValue(m_current);
shift();
--maximumDigits;
} while (isASCIIHexDigit(m_current) && maximumDigits >= 0);
if (maximumDigits >= 0) {
returnValue = hexValue;
return;
}
// maximumDigits如果小于0,说明4个字节存放不下了
// No more place in the hexValue buffer.
// The values are shifted out and placed into the m_buffer8 vector.
// 将前面解析好的部分16进制字符存放到m_buffer8中
for (int i = 0; i < 8; ++i) {
int digit = hexValue >> 28;
if (digit < 10)
record8(digit + '0');
else
record8(digit - 10 + 'a');
hexValue <<= 4;
}
// 继续将后面的16进制字符添加到m_buffer8中
while (isASCIIHexDigit(m_current)) {
record8(m_current);
shift();
}
// 调用parseIntOverflow解析16进制
returnValue = parseIntOverflow(m_buffer8.data(), m_buffer8.size(), 16);
}
8进制解析
一样的套路,不再赘言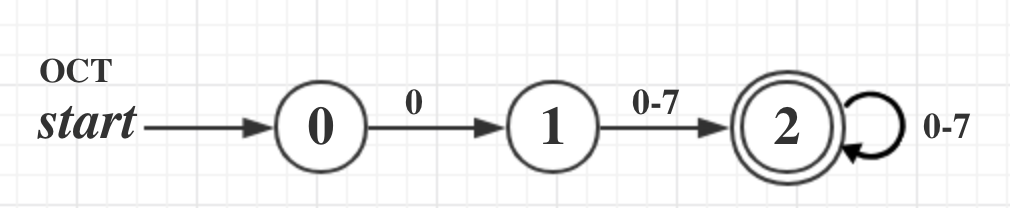
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37template <typename T>
ALWAYS_INLINE bool Lexer<T>::parseOctal(double& returnValue)
{
// Optimization: most octal values fit into 4 bytes.
uint32_t octalValue = 0;
const unsigned maximumDigits = 10;
int digit = maximumDigits - 1;
// Temporary buffer for the digits. Makes easier
// to reconstruct the input characters when needed.
LChar digits[maximumDigits];
do {
octalValue = octalValue * 8 + (m_current - '0');
digits[digit] = m_current;
shift();
--digit;
} while (isASCIIOctalDigit(m_current) && digit >= 0);
if (!isASCIIDigit(m_current) && digit >= 0) {
returnValue = octalValue;
return true;
}
for (int i = maximumDigits - 1; i > digit; --i)
record8(digits[i]);
while (isASCIIOctalDigit(m_current)) {
record8(m_current);
shift();
}
if (isASCIIDigit(m_current))
return false;
returnValue = parseIntOverflow(m_buffer8.data(), m_buffer8.size(), 8);
return true;
}
N进制整数溢出解析
接下来就是标准的整数解析过程了,2进制、8进制、10进制和16进制的整数,都可以通过此函数进行解析,radix代表进制1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21double parseIntOverflow(const LChar* s, unsigned length, int radix)
{
double number = 0.0;
double radixMultiplier = 1.0;
for (const LChar* p = s + length - 1; p >= s; p--) {
if (radixMultiplier == std::numeric_limits<double>::infinity()) {
if (*p != '0') {
number = std::numeric_limits<double>::infinity();
break;
}
} else {
int digit = parseDigit(*p, radix);
number += digit * radixMultiplier;
}
radixMultiplier *= radix;
}
return number;
}
小数点和指数解析
用DFA转移图来表示下浮点数的解析: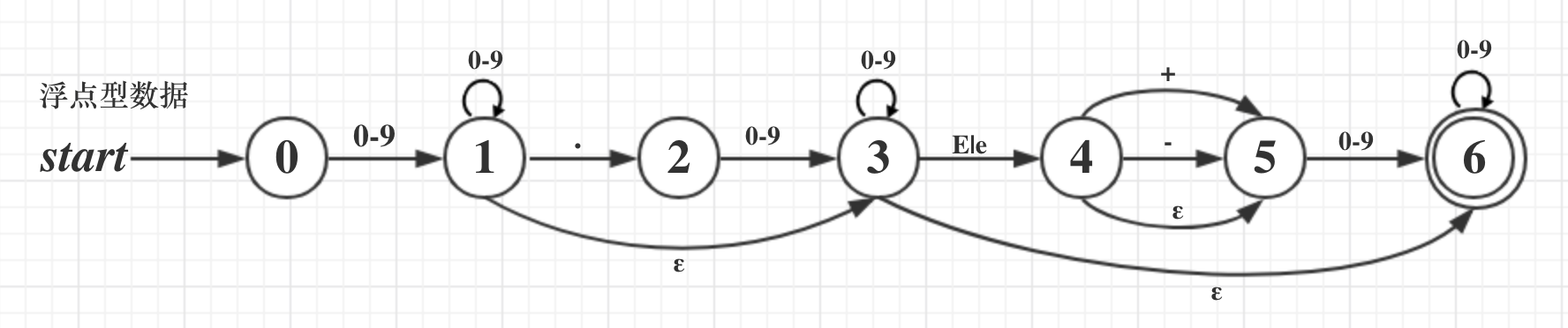
1 | template <typename T> |
多行注释解析
多行注释的DFA转移图: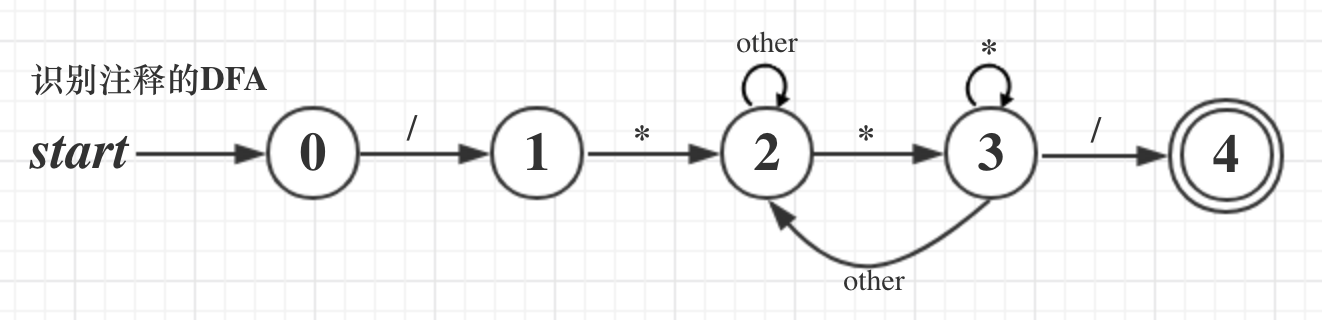
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27template <typename T>
ALWAYS_INLINE bool Lexer<T>::parseMultilineComment()
{
while (true)
{
// 寻找离开始的/*最近的*/(*和/必须紧挨着)
while (UNLIKELY(m_current == '*')) {
shift();
if (m_current == '/') {
shift();
return true;
}
}
// 偏移结束位置,异常
if (atEnd()) return false;
if (isLineTerminator(m_current)) {
// 行末,跳过
shiftLineTerminator();
m_terminator = true;
} else{
// 直接跳过当前字符
shift();
}
}
}
示例(更新)
例如有这么一段js代码,包含一个函数、一个变量以及函数的调用1
2
3
4
5
6
7
8function test(age){
if(age > 10){
console.log(age);
}
}
var age = 6 * 7;
test(age);
在经过Esprima词法分析后,会得到下面的结果:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138[
{
"type": "Keyword",
"value": "function"
},
{
"type": "Identifier",
"value": "test"
},
{
"type": "Punctuator",
"value": "("
},
{
"type": "Identifier",
"value": "age"
},
{
"type": "Punctuator",
"value": ")"
},
{
"type": "Punctuator",
"value": "{"
},
{
"type": "Keyword",
"value": "if"
},
{
"type": "Punctuator",
"value": "("
},
{
"type": "Identifier",
"value": "age"
},
{
"type": "Punctuator",
"value": ">"
},
{
"type": "Numeric",
"value": "10"
},
{
"type": "Punctuator",
"value": ")"
},
{
"type": "Punctuator",
"value": "{"
},
{
"type": "Identifier",
"value": "console"
},
{
"type": "Punctuator",
"value": "."
},
{
"type": "Identifier",
"value": "log"
},
{
"type": "Punctuator",
"value": "("
},
{
"type": "Identifier",
"value": "age"
},
{
"type": "Punctuator",
"value": ")"
},
{
"type": "Punctuator",
"value": ";"
},
{
"type": "Punctuator",
"value": "}"
},
{
"type": "Punctuator",
"value": "}"
},
{
"type": "Keyword",
"value": "var"
},
{
"type": "Identifier",
"value": "age"
},
{
"type": "Punctuator",
"value": "="
},
{
"type": "Numeric",
"value": "6"
},
{
"type": "Punctuator",
"value": "*"
},
{
"type": "Numeric",
"value": "7"
},
{
"type": "Punctuator",
"value": ";"
},
{
"type": "Identifier",
"value": "test"
},
{
"type": "Punctuator",
"value": "("
},
{
"type": "Identifier",
"value": "age"
},
{
"type": "Punctuator",
"value": ")"
},
{
"type": "Punctuator",
"value": ";"
}
]
总结
经过此过程,一个完整的JSC世界的Token就生成了,整个世界清静了…

