前言
不知不觉又到了挖坑季节,作为一个菜鸟,我愿意给自己一个机会,督促自己的学习和总结,同时也给自己一个挑战,从JavaScriptCore的开源代码中剖析它的实现原理。(本系列的文章尽量会写的有血有肉,内容会随时保持更新)
JavaScriptCore简介
JavaScriptCore是苹果开源项目WebKit中的默认JavaScript引擎,被用来解释和执行JavaScript代码。一开始它是基于KJS开发的,是基于抽象语法树的解释器,性能较差。2008年苹果重写了编译器和字节码解释器,叫SquirrelFish:
SquirrelFish is a register-based, direct-threaded(bigger code and data, but fast), high-level bytecode engine, with a sliding register window calling convention. It lazily generates bytecodes from a syntax tree, using a simple one-pass compiler with built-in copy propagation.
源码目录结构
- API:各种JavaScriptCore对外的接口类
- assembler:汇编器,用于生成各个平台的汇编代码
- b3:ftl 里的 Backend
- bytecode:字节码的内容,比如类型和计算过程
- bytecompiler:编译字节码
- Configurations:Xcode 的相关配置
- Debugger:用于测试脚本的程序
- dfg:DFG JIT 编译器
- disassembler:反汇编
- heap:运行时的堆和垃圾回收机制
- ftl:第四层编译
- interpreter:解释器,负责解析执行 ByteCode
- jit:在运行时将 ByteCode 转成机器码,动态及时编译。
- llint:Low Level Interpreter,编译四层里的第一层,负责解释执行低效字节码
- parser:词法语法分析,构建语法树
- profiler:信息收集,能收集函数调用频率和消耗时间。
- runtime:运行时对于 js 的全套操作。
- wasm:对 WebAssembly 的实现。
- yarr:Yet Another Regex Runtime,运行时正则表达式的解析
核心模块
该部分内容主要翻译自官方文档
JavaScriptCore是一个高度优化的虚拟机,主要包括以下几个模块:
Lexer 词法分析器,将JavaScript源码分解成Tokens,代码文件:parser/Lexer.cpp.
Parse 语法分析器,基于Lexer的Tokens生成语法分析树,手写了递归下降解析器,代码文件:parser/Parser.cpp.
LLInt
Low Level Interpreter,执行Parser生成的字节码。代码在 llint/ 里,应用一个可移植的汇编实现,也被为offlineasm (代码在offlineasm/目录下), 它可以编译为x86和ARMv7的汇编以及C代码。LLInt除了词法解析和语法解释外,JIT编译器所执行的调用、栈、以及寄存器转换都是基本没有启动开销(start-up cost)的。比如,调用一个LLInt函数就和调用一个已被编译原始代码的函数相似, 除非机器码的入口恰是一个共用的LLInt Prologue(公共函数头,shared LLInt prologue). LLInt还包括了一些优化,比如应用inline cacheing来加速属性访问.Baseline JIT 在函数被调用了6次,或者某段代码循环了100次后(也可能是一些组合,比如3次带有50次枚举的调用)就会触发
Baseline JIT。这些数字只是大概的估计,实际上的启发(heuristics)过程是依赖于函数大小和当时内存状态的。当JIT卡在一个循环时,它会执行On-Stack-Replace(OSR)将函数的全部调用者从新指向新的编译代码。Baseline JIT同时也是函数进一步优化的后备,如果没法优化代码时,它还会通过OSR调整到Baseline JIT. BaseLine JIT的代码在 jit/ . 基线JIT也为inline caching执行几乎全部的堆访问DFG JIT 在函数被调用了至少60次,或者代码循环了1000次,就会触发DFG JIT。一样,这些都是近似数,整个过程也是趋向于启发式的。DFG积极地基于前面(baseline JIT&Interpreter)收集的数据停止类型揣测,这样就可以尽早获得类型信息(forward-propagate type information),从而减少了大批的类型检查。DFG也会自行停止揣测,比如为了启用inlining, 可能会将从heap中加载的内容识别出一个已知的函数对象。如果揣测失败,DFG取消优化(Deoptimization),也称为”OSR exit”. Deoptimization可能是同步的(某个类型检测分支正在执行),也可能是异步的(比如runtime视察到某个值变化了,并且与DFG的假设是冲突的),后者也被称为”watchpointing”。
Baseline JIT和DFGJIT共用一个双向的OSR:Baseline可以在一个函数被频繁调用时OSR进入DFG, 而DFG则会在deoptimization时OSR回到Baseline JIT. 反复的OSR退出(OSR exits)还有一个统计功能: DFG OSR退出会像记载发生频率一样记载下退出的理由(比如对值的类型揣测失败), 如果退出一定次数后,就会引发从新优化(reoptimization), 函数的调用者会从新被定位到Baseline JIT,然后会收集更多的统计信息,或许根据需要再次调用DFG。从新优化应用了指数式的回退策略(exponential back-off,会越来越来)来应对一些奇葩代码。DFG代码在dfg/.FTL 高吞吐量优化 JIT,全称 Faster Than Light,DFG 高层优化配合 B3 底层优化。以前全称是 Fourth Tier LLVM 底层优化使用的是 LLVM。B3 对 LLVM 做了裁剪,对 JavaScriptCore 做了特性处理,B3 IR 的接口和 LLVM IR 很类似。B3 对 LLVM 的替换主要是考虑减少内存开销,LLVM 主要是针对编译器,编译器在这方面优化动力必然没有 JIT 需求高。B3 IR 将指针改成了更紧凑的整数来表示引用关系。不可变的常用的信息使用固定大小的结构来表示,其它的都放到另外的地方。紧凑的数据放到数组中,更多的数组更少的链表。这样形成的 IR 更省内存
任何时候,函数, eval代码块,以及全局代码(global code)都可能会由LLInt, Baseline JIT和DFG三者同时运行。一个极端的例子是递归函数,因为有多个stack frames,就可能一个运行在LLInt下,另一个运行在Baseline JIT里,其它的可能正运行在DFG里。更为极端的情况是当从新优化在执行过程被触发时,就会出现一个stack frame正在执行本来旧的DFG编译,而另一个则正执行新的DFG编译。为此三者计划成维护雷同的执行语义(execution semantics), 它们的混合应用也是为了带来显著的效能提升。
工作流程图
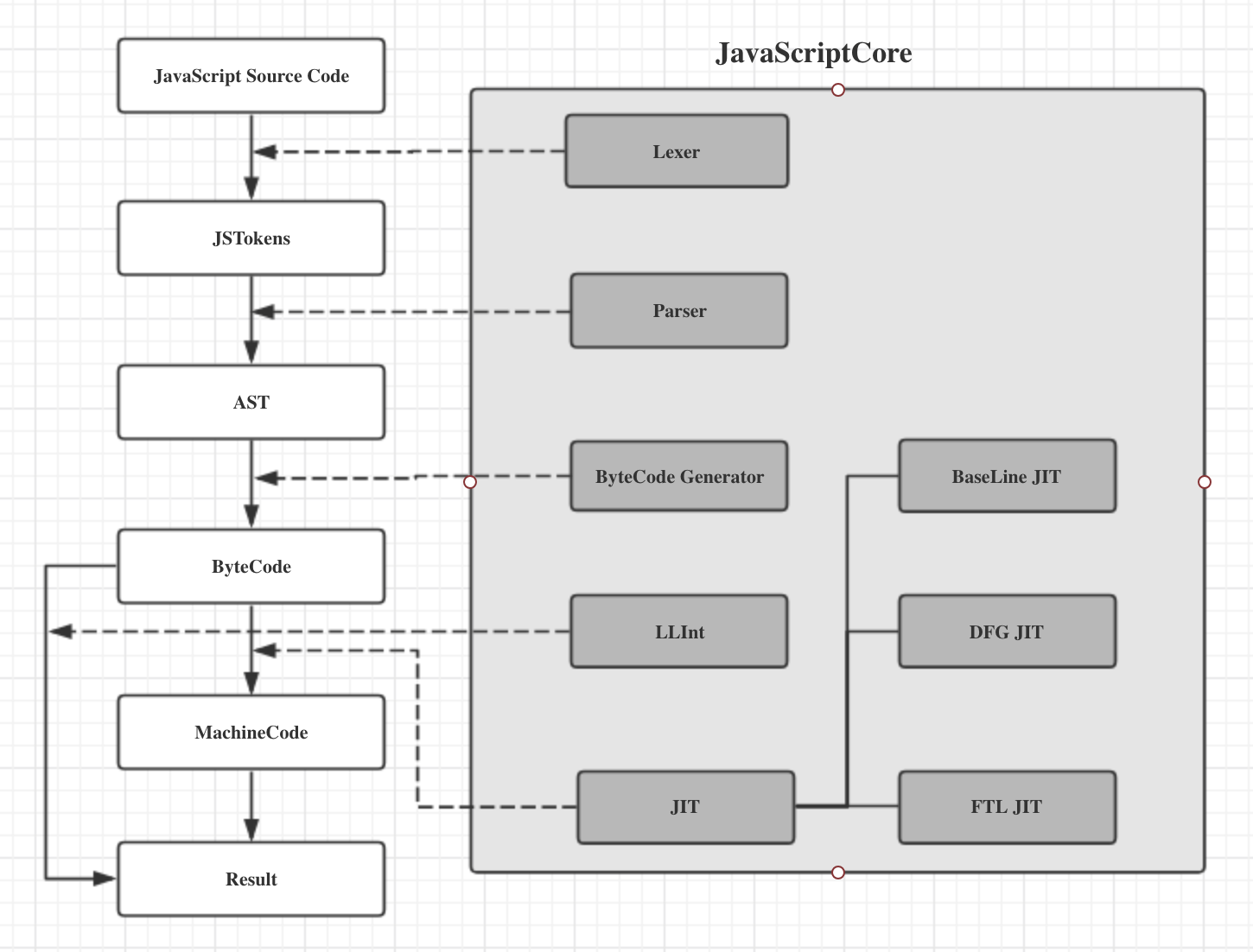
执行的基础环境
JSC解析生成的代码放到一个虚拟机上来执行(广义上讲JSC主身就是一个虚拟机)。JSC使用的是一个基于寄存器的虚拟机(register-based VM),另一种实现方式是基于栈的虚拟机(stack-based VM)。两者的差异可以简单的理解为指令集传递参数的方式,是使用寄存器,还是使用栈。
相对于基于栈的虚拟机,因为不需要频繁的压、出栈,以及对三元操作的支持,register-based VM的效率更高,但可移植性相对弱一些。
所谓的三元操作符,其中add就是一个三元操作,add dst, src1, src2,功能是将src1与src2相加,将结果保存在dst中。dst, src1,src2都是寄存器。
参考JSC字节码规格,给出两个示例:1
2
3
4new_array
Format: new_array dst(r) firstArg(r) argCount(n)
Constructs a new Array instance using the original constructor, and puts the result in register dst. The array will contain argCount elements with values taken from registers starting at register firstArg.
1 | add |
而基于栈的虚拟机的生成的字节码如下:1
2
3
4
5
6
7
8
9
10
110: iconst_1
1: istore_0
2: iconst_2
3: istore_1
4: iload_0
5: iload_1
6: iadd
7: iconst_5
8: imul
9: istore_2
10: return
可以体会下这两种方式的不同
从JS Script到Byte Code
首先说明Lexer, Parser和ByteCode的生成都是由ProgramExecutable初始化过程完成的。首先在JSC的API evaluate()中会创建ProgramExecutable并指定脚本代码。然后传入Interpreter时,再透过CodeCache获取的UnlinkedProgramCodeBlock就是已经生成ByteCode后的Code Block了。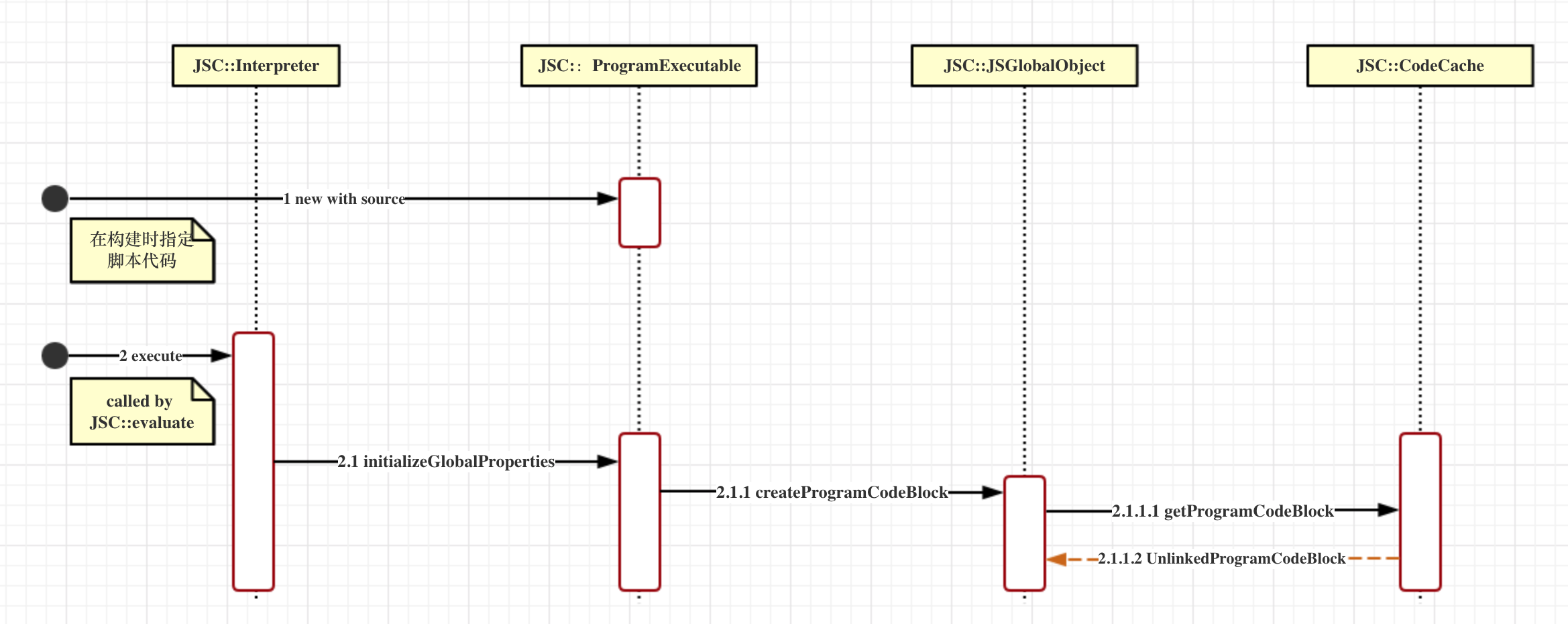
下图是CodeCache调用Parser和ByteCodeGenerator的序列图: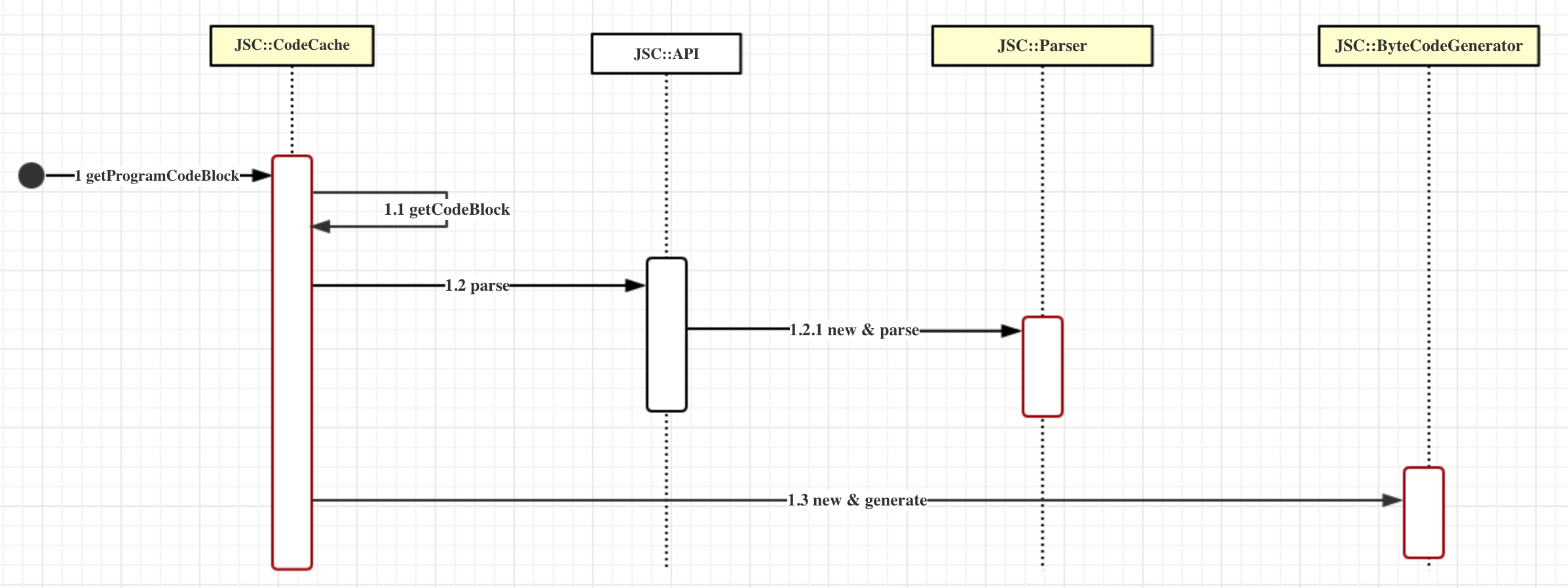
而Lexer则是在Parser过程中调用的,如下图: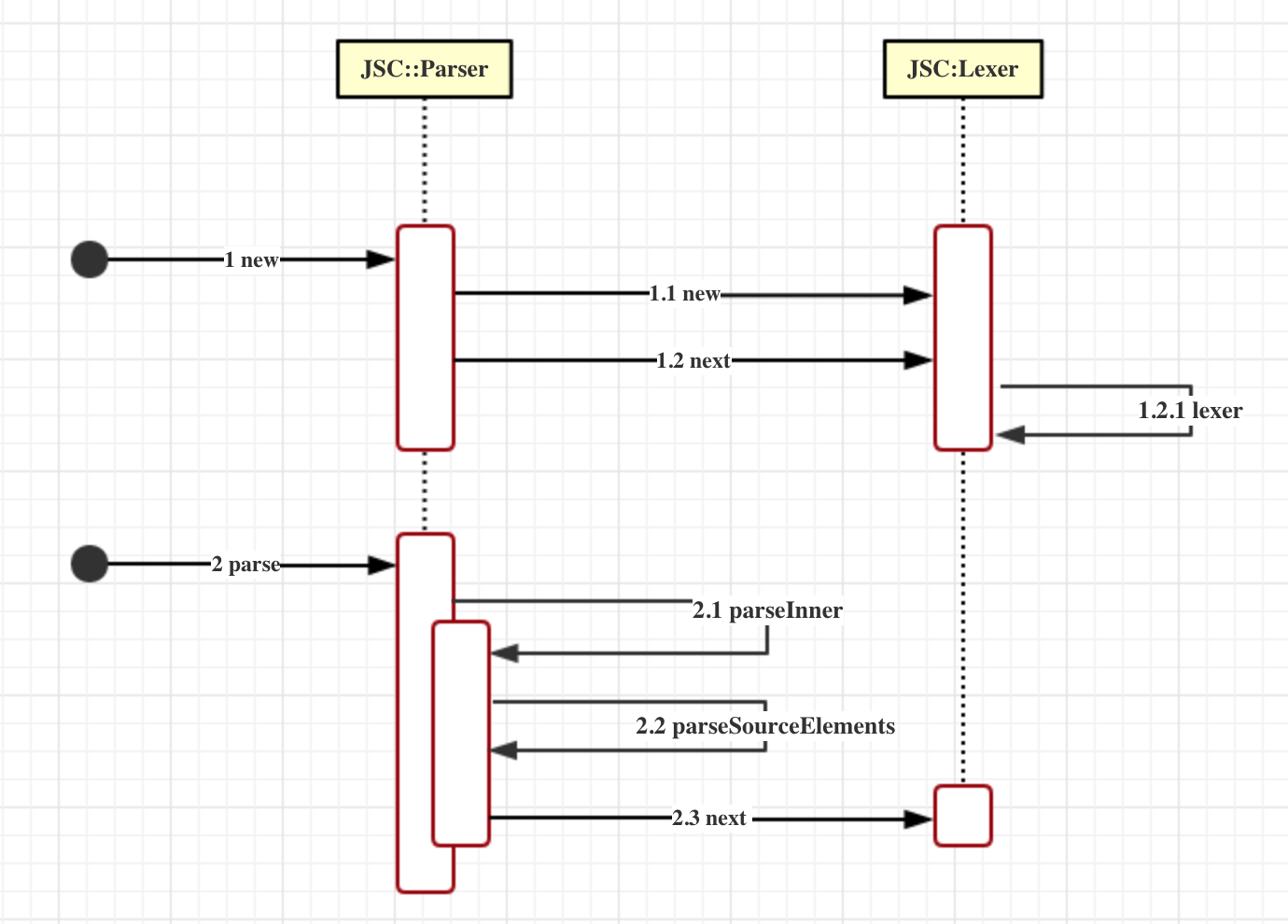
更具体的细节会在随后会在对应的篇章中进行分析

